Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Příklad úlohy pro analytickou proceduru a modul MCluster-Miner.
Položíme si hlavní a dodatečnou analytickou otázku:
Podobnost budeme chápat ve smyslu euklidovské vzdálenosti. Jako kritérium vhodného rozdělení pak co nejnižší podíl součtu vnitroshlukových vzdáleností ku součtu mezishlukové vzdálenosti.
Formálně můžeme otázku zapsat takto:
kde Hotel jsou analyzovaná data, MCluster určuje použitou GUHA-proceduru, DHodnoceni je cílový atribut, ID/ED je použitá metrika, kterou se snažíme minimalizovat, a na závěr je uveden seznam vysvětlujících atributů použitelných pro shlukování.
Algoritmus k-Means pro shlukování byl navržen primárně pro spojité numerické veličiny. Požadavek systému LISp-Miner nejprve převést všechny spojité veličiny na diskrétní vyřešíme tak, že hodnoty spojité veličiny diskretizujeme na větší množství ekvidistantních intervalů. Budou tak dostatečně jemné (krátké), aby i tak dobře charakterizovaly spojitou veličinu. Ukazuje se, že dostatečný je už počet dvaceti ekvidistantních intervalů.
Pro všechny čtyři sloupce dílčího hodnocení jsme již ve fázi Předzpracování vytvořili atributy s kategorizací na dostatečně krátké intervaly, ve které jsme při automatickém vytváření kategorií zvolili Equidistant intervals s počtem 20. Pro snadnou identifikaci jsme použili název s příponou _edc20, např. DUbytovani_edc20.
V případě, že bychom pro shlukování chtěli použít nominální veličiny (v této ukázce tomu tak není), tak bychom pro ně museli vytvořit i dichotomické atributy – viz také Tipy a doporučení pro MCluster-Miner.
Že vyplněná dílčí hodnocení tvoří shluky a že tyto shluky poměrně dobře korespondují s celkovým hodnocením jsme zjistili už pomocí interaktivní analýzy hlavních komponent.
V té však byly použity všechny atributy, možná by jich však stačilo méně. U pouhých čtyř atributů by bylo možné ručně vyzkoušet všechny kratší kombinace, ale i tak by to bylo pracné. U většího množství atributů je to už prakticky nemožné.
Výhodou je, že analytická procedura MCluster-Miner za nás bude automaticky a systematicky procházet všechny možné kombinace vstupních atributů a testovat, jak dobře lze podle nich vyplněné dotazníky rozdělit do shluků.
Před zadáváním úlohy vytvoříme nejprve novou skupinu úloh, kterou pojmenujeme podle analytické otázky, na kterou bude úloha (resp. úlohy) hledat odpověď – v tomto případě 04: Shluková analýza dílčích hodnocení.
Číselný prefix 04 v názvu odkazuje na číslo analytické úlohy a zároveň zajistí řazení skupin v seznamu podle analytických otázek.
Nyní již přidáme novou úlohu pro analytickou proceduru MCluster-Miner a nazveme ji 04.01: DUbytovani, DStrava, DPersonal, DZabava, aby z jejího názvu bylo jednak opět patrné, že odpovídá na čtvrtou analytickou otázku (resp. její první část), ale i to, jaké jsou použité atributy.
V základních parametrech úlohy po zadání názvu ještě změníme příslušnost úlohy do skupiny, kterou jsme přidali před chvílí.
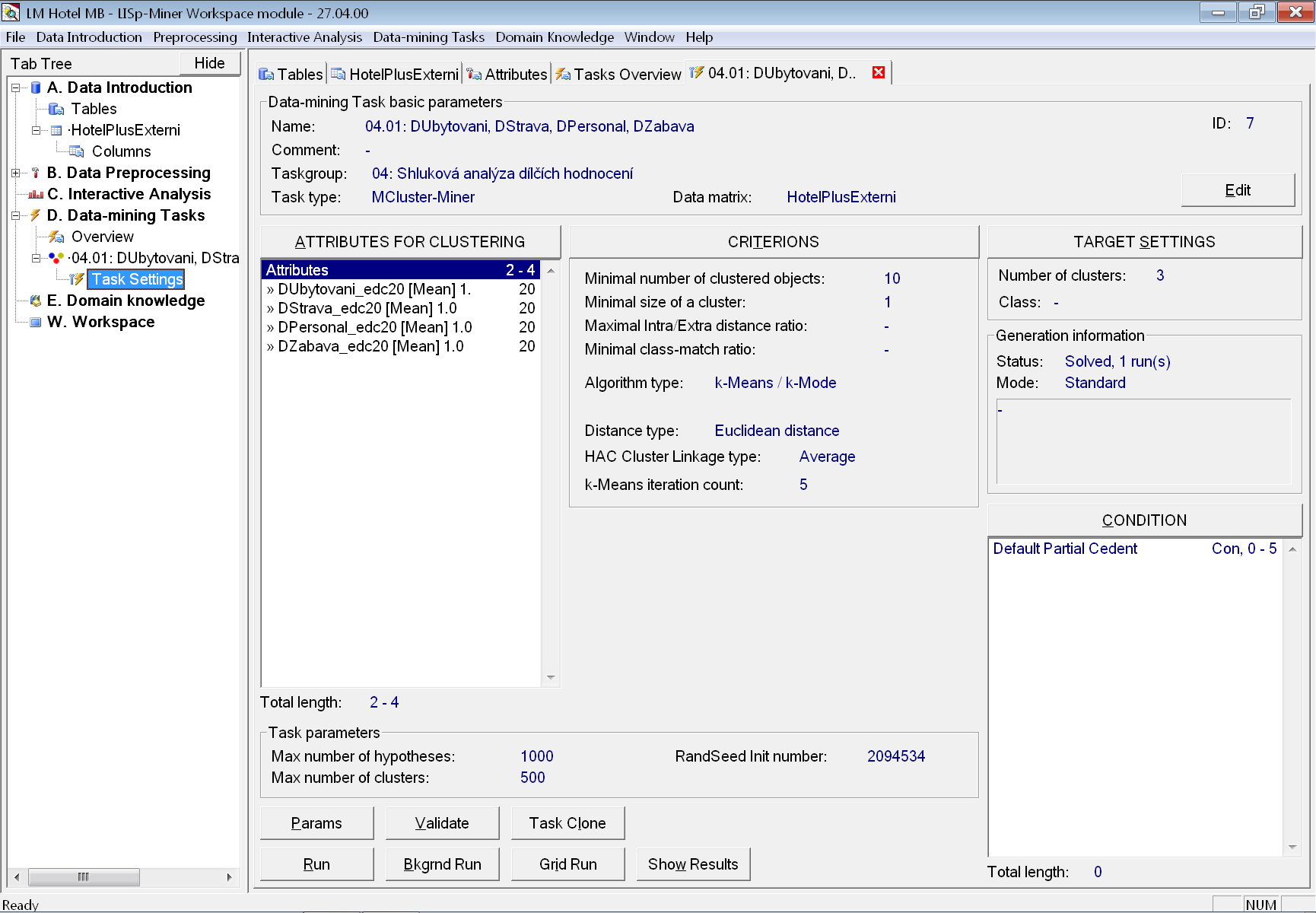
Ukázku úplného zadání úlohy (po provedení všech kroků uvedených níže) vidíme na obrázku.
V seznamu atributů použitelných pro shlukování jsou uvedeny všechna dostupná dílčí hodnocení. Pro snadný zpětný převod z ordinálních na numerické hodnoty byly použity ve fázi předzpracování připravené atributy s dvaceti ekvidistantními intervaly.
Všechny čtyři atributy byly přidány najednou jejich současným označením ve stromu skupin a do nich patřících atributů (pomocí klávesy Ctrl). V zadání parametrů pro první z přidávaných atributů bylo ponecháno výchozí nastavení výpočtu průměru (angl. Mean), povolení desetinných čísel při výpočtu středů a váha. Pouze z kosmetických důvodů bylo pořadí atributů změněno pomocí tlačítek Up a Down, aby odpovídalo pořadí dílčích hodnocení v dotazníku a v názvu úlohy.
Protože nevíme, kolik z těchto čtyř atributů je pro kvalitní rozdělení do shluků skutečně potřeba, ponecháme přednastavené povolené rozpětí od 2 (minimální možný počet atributů pro shlukování) do 4 (celkový počet atributů). Při výpočtu úlohy budou postupně generovány varianty shlukování pro všechny možné kombinace atributů ze seznamu o délce dva až čtyři. Ve výsledku se pak seřadí od nejlepší po nejhorší.
V parametrech kritérií není zadána požadovaná minimální kvalita shlukování a ponechán byl i přednastavený typ algoritmu k-Means/k-Mode a způsob měření podobnosti Euclidean distance.
Důležitým parametrem nehierarchického shlukování je požadovaný počet shluků. Protože víme, že v datech jsou právě tři možné hodnoty celkového hodnocení, je přirozenou počáteční volbou zadat i stejný cílový počet shluků. Zadáme tedy hodnoty 3 do políčka pro minimální i pro maximální počet. Někdy však může být vhodné nechat shlukovacímu algoritmus volnost, aby v datech nalezl přirozené shluky, kterých může být více, či méně.
Tím je zadání úlohy pro MCluster-Miner připraveno. Všimněme si ještě automaticky nastavené počáteční hodnoty RandSeed Init number pro generátor pseudonáhodných čísel.
Před spuštěním výpočtu ověříme tlačítkem Validate, že jsme neopomněli žádnou nezbytnou část zadání. Potom spustíme výpočet tlačítkem Run.
Po skončení výpočtu se výsledky zobrazí na záložce Task Results.
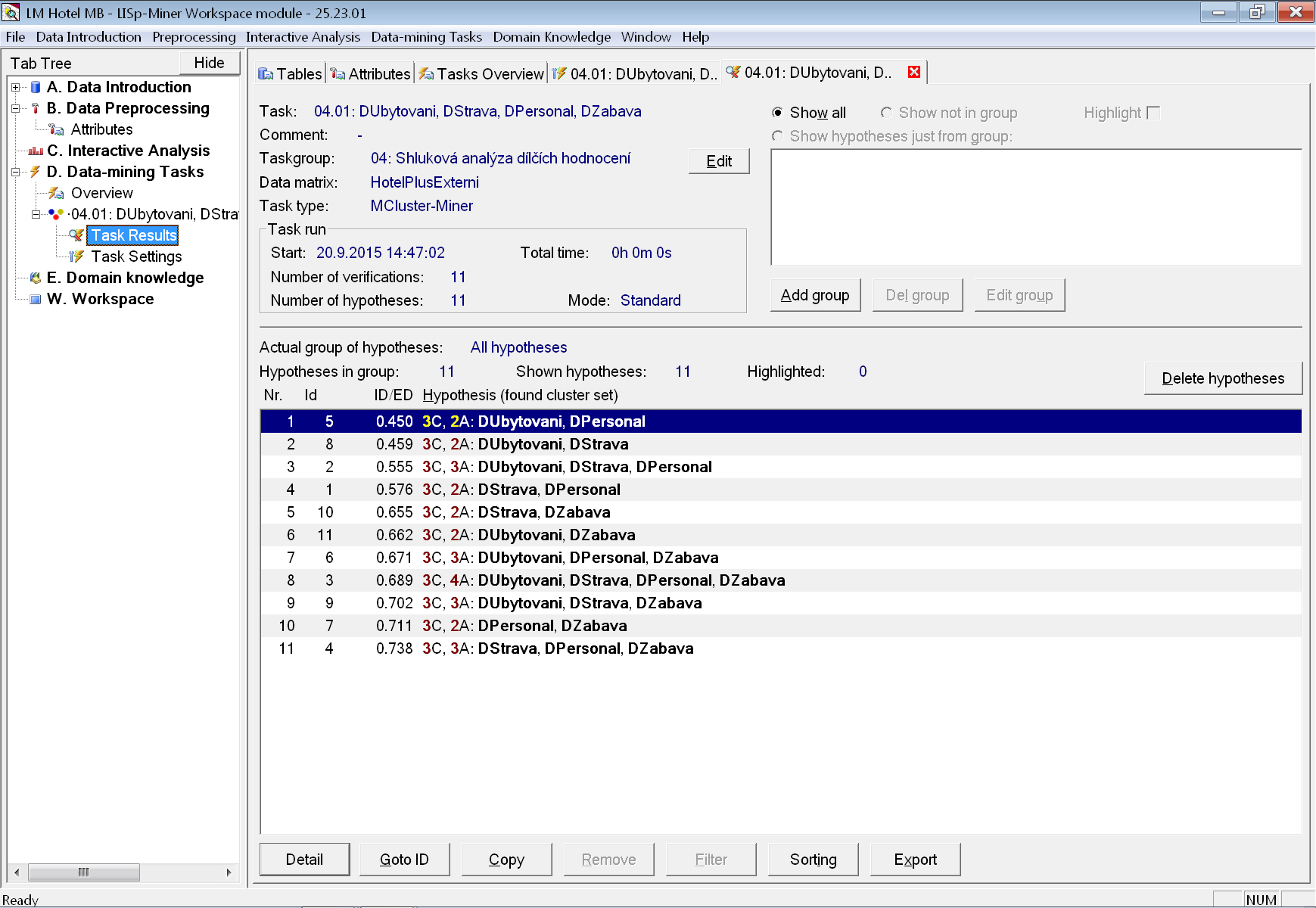
Na obrázku vidíme celkem jedenáct nalezených variant shlukování lišících se kombinací použitých atributů, a tím také výslednou kvalitou ve smyslu poměru součtu vnitroshlukových a mezishlukových vzdáleností. Všechny varianty však nalezly požadovaný počet tří shluků. Jako nejlepší varianta se jeví použití pouze dílčích hodnocení DUbytovani a DPersonal.
Všimněme si také, že ve výsledcích se nezobrazují sufixy použité pro vyjádření způsobu předzpracování atributů, které by mohly majitele dat mást. Toho jsme docílili zadáním alternativního názvu atributu.
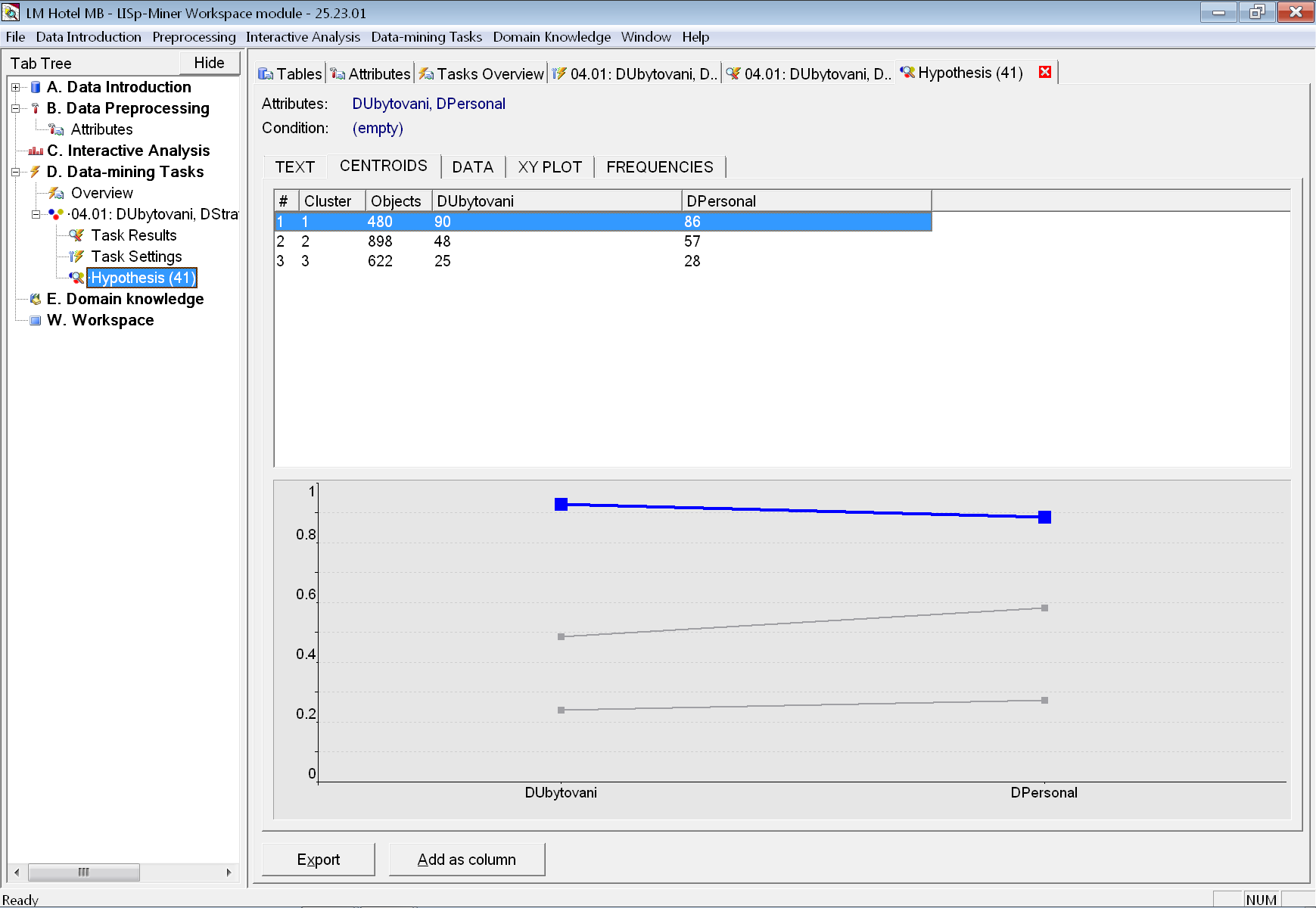
Po otevření záložky s detailem varianty vidíme, že opravdu byly nalezeny tři shluky, jak bylo požadováno. V prvním shluku je 480 záznamů s převážně dobrým dílčím hodnocením (průměrná hodnota pro dílčí hodnocení DUbytovani je 90 % a pro DPersonal pak 86 %). V druhé shluku je 898 záznamů s převážně průměrným dílčím hodnocením (48 % a 57 %), i když dílčí hodnocení personálu je téměř o 10 procentních bodů lepší, než dílčí hodnocení ubytování. V posledním, třetím shluku je 622 záznamů se spíše špatným dílčím hodnocením (25 % a 28 %).
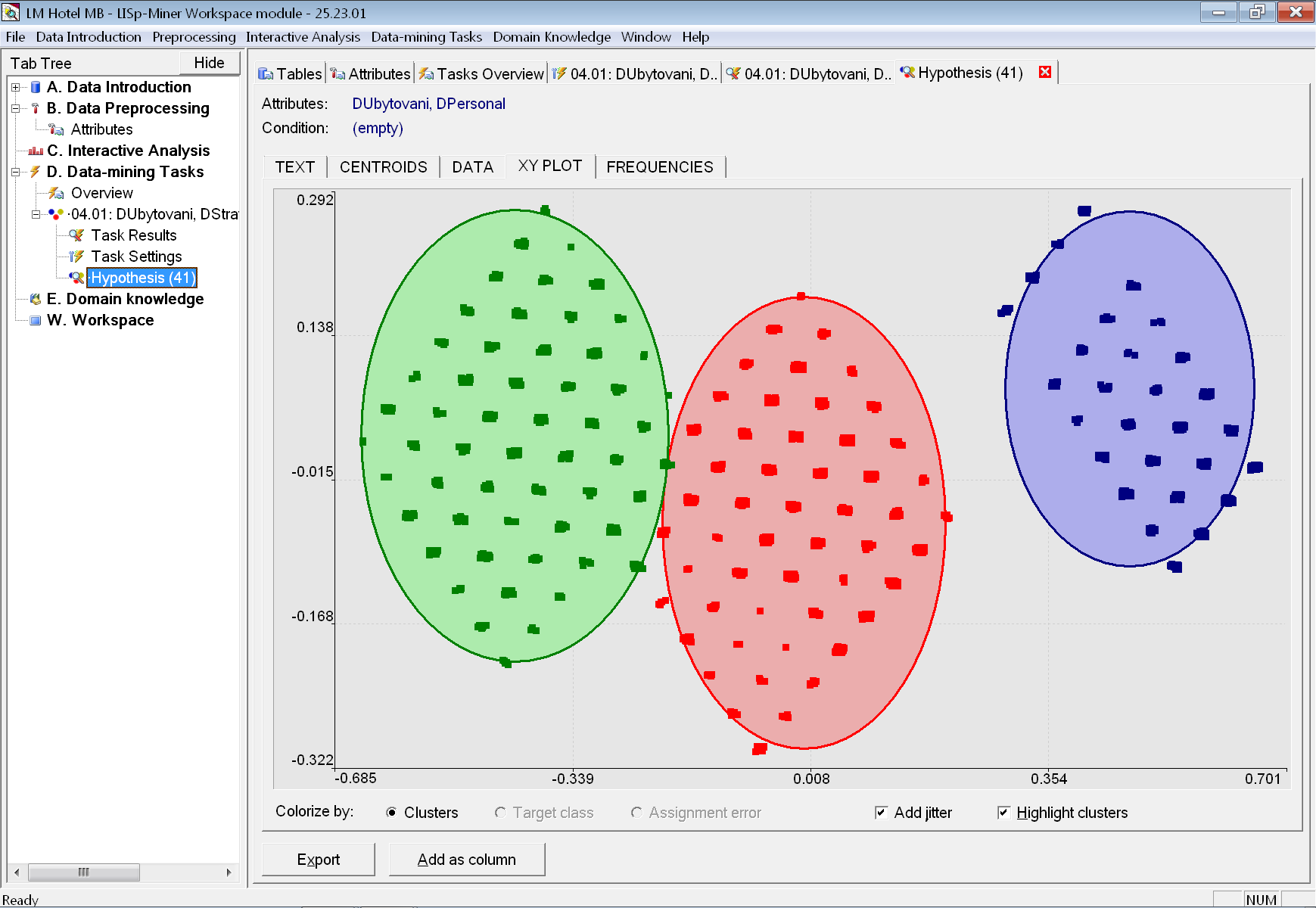
Po přepnutí na dílčí záložku XY PLOT s hlavními komponentami podle PCA vidíme, že nejmenší shluk (s dobrým hodnocením) se výrazně odlišuje od zbylých dvou shluků. Ty mají k sobě relativně blízko.
Tím je vyřešena první část položené analytické otázky.
![]() MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 01 (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 01 (Hotel.MBVC.zip)
Doposud jsme nepracovali s hodnotami celkového hodnocení. Přepneme se tedy na záložku s detaily zadání úlohy a vytvoříme klon úlohy.
Novou úlohu nazveme 04.02: DHodnoceni: DUbytovani, DStrava, DPersonal, DZabava. V názvu je navíc DHodnoceni, abychom ji odlišili od původní úlohy. Tento atribut nastavíme i jako cílovou třídu v dialogovém okně Target Settings pomocí tlačítka Attribute.
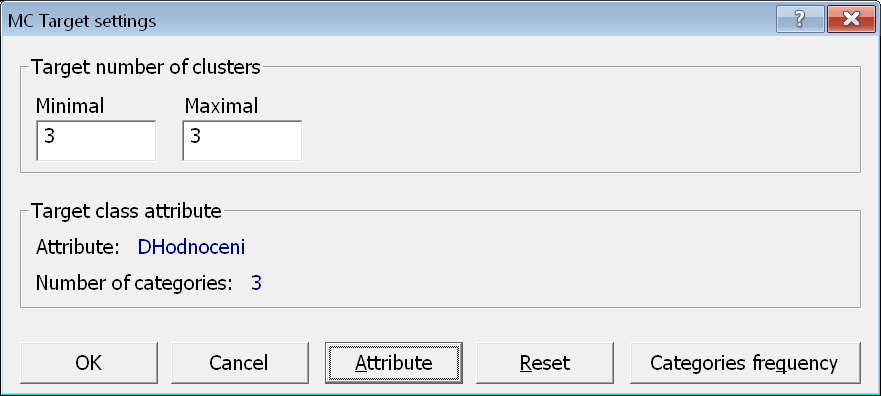
Po spuštění a skončení výpočtu se výsledky zobrazí na záložce Task Results.
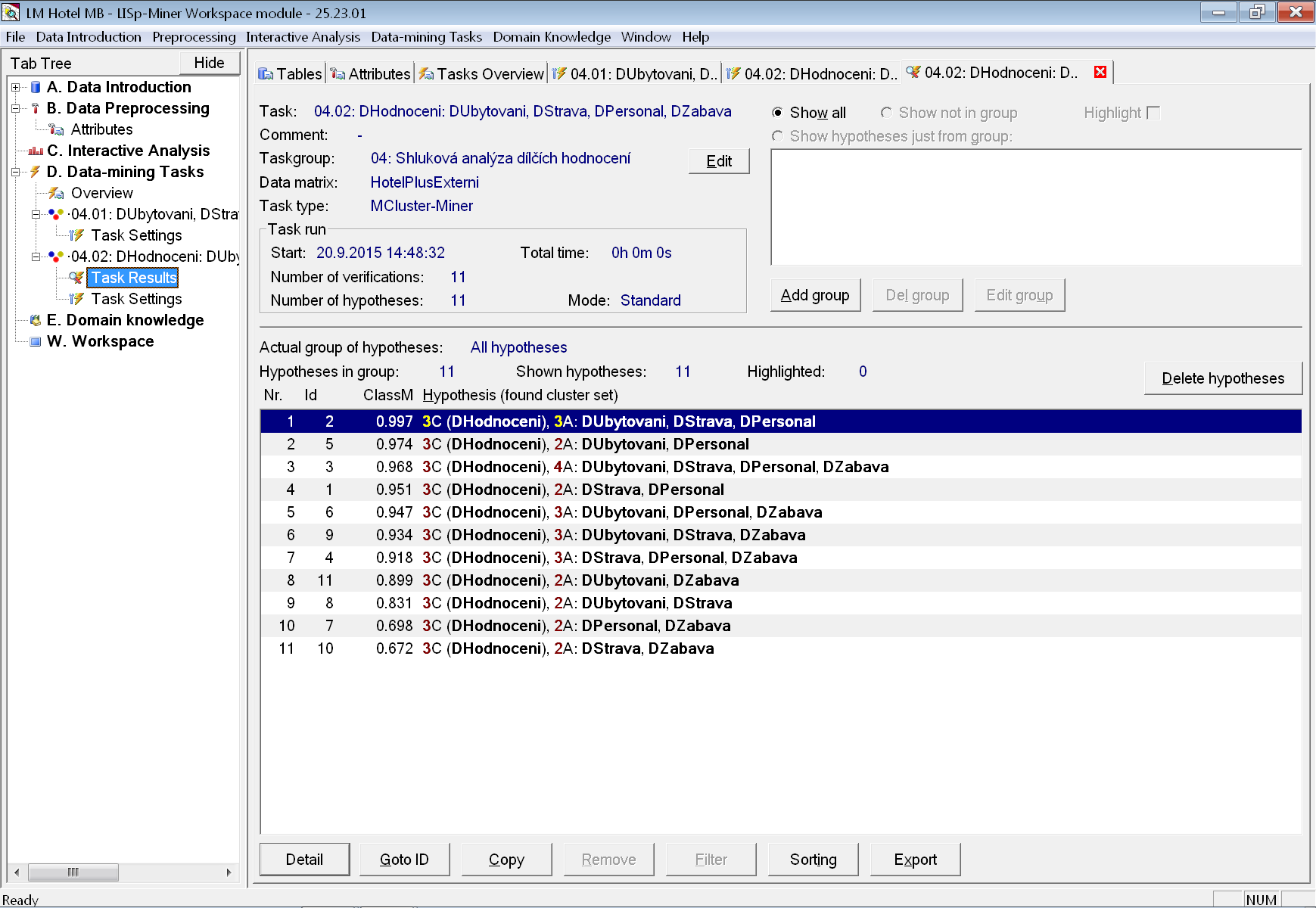
Vidíme, že počet nalezených variant shlukování zůstal stejný, ale změnilo se pořadí variant. Tentokrát jsou totiž setříděny podle kvality příslušnosti záznamů do zadané cílové třídy. Před původně nejlepší variantu se dvěma atributy se tak dostala varianta používající atributy tři – DUbytovani, DStrava a DPersonal. Toto rozdělení záznamů do třech shluků přiřadí záznam ke správné cílové třídě v 99,7 % případů.
Po otevření záložky s detailem hypotézy pro nejlepší variantu opět vidíme na záložce CENTROIDS počty záznamů patřících do jednotlivých shluků i typické hodnoty dílčích hodnocení. Navíc je uvedena i převažující cílová třída v každém shluku.
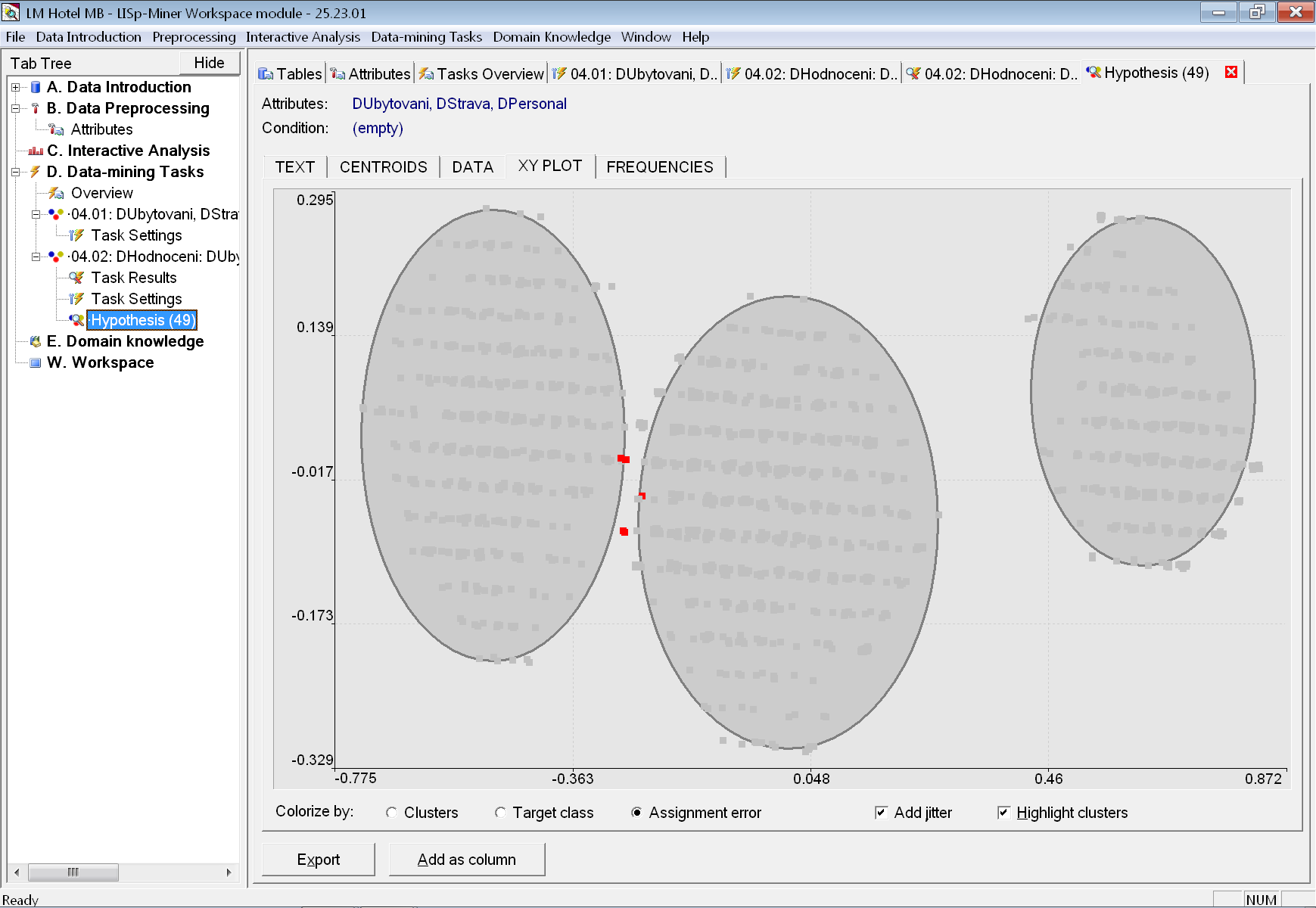
Po přepnutí na záložku XY Plot můžeme změnit způsob obarvení volbou Colorized by na hodnotu Assigment error. Červeně je nyní zvýrazněno pět záznamů, které byly chybně přiřazeny do shluku, který neodpovídá expertnímu přiřazení z atributu DHodnoceni.
O které konkrétně záznamy jde, zjistíme na záložce DATA, kde jsou také zvýrazněny červeně.
![]() MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 02 (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 02 (Hotel.MBVC.zip)
Odpověď na hlavní analytickou otázky tedy zní „Kombinace dílčích hodnocení ve vyplněných dotaznících tvoří přirozené shluky.“ A i odpověď na druhou, doplňující otázku je kladná – „Kombinace dílčích hodnocení s přesností na 99,7 % korespondují s celkovým hodnocením. K tomu stačí použít pouze tři dílčí hodnocení – DUbytovani, DStrava a DPersonal.“
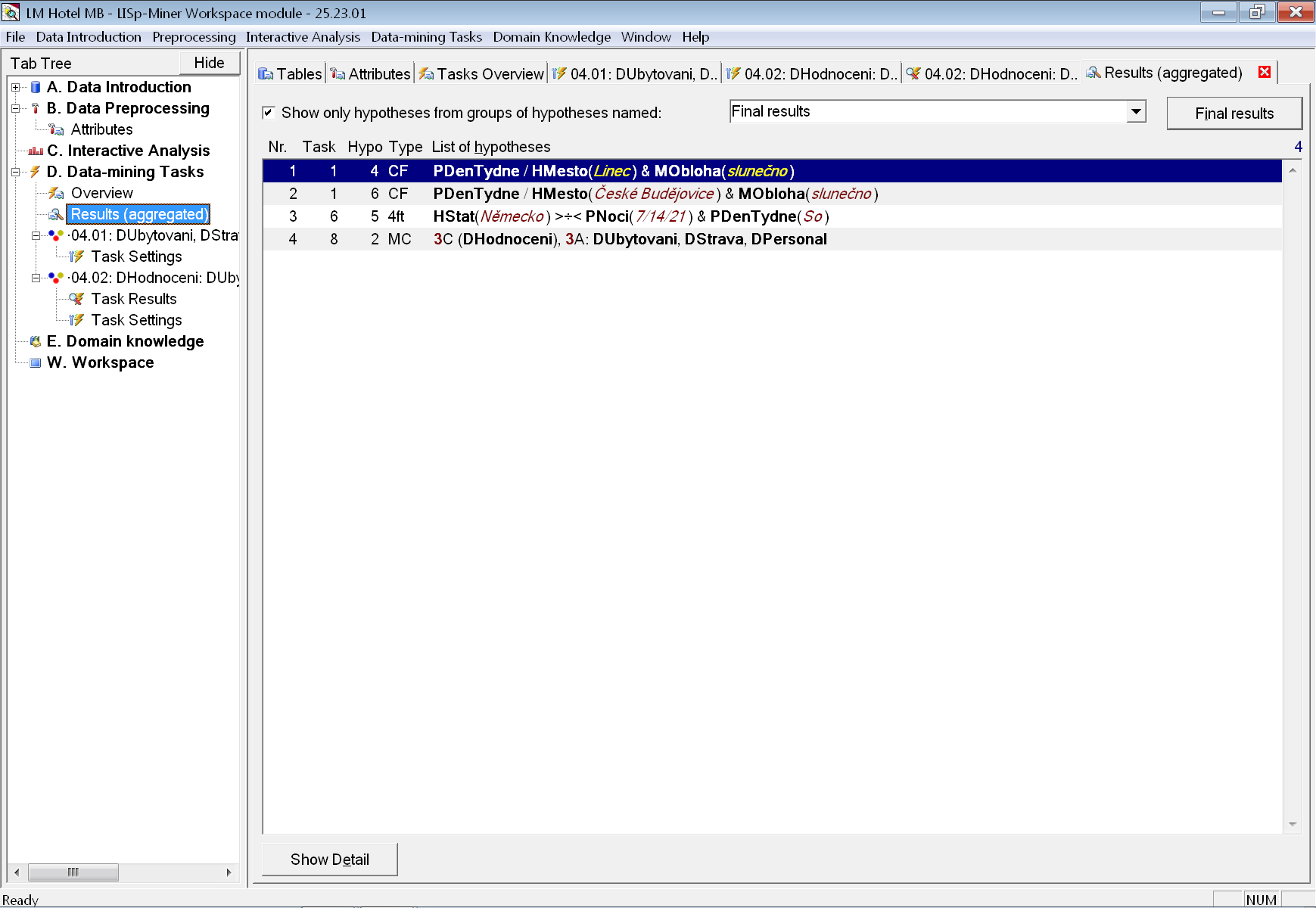
Pro zahrnutí do výsledné analytické zprávy zvolíme nejlepší nalezený výsledek shlukování ve druhé úloze. Pomocí tlačítka Copy jej vložíme do skupiny hypotéz s názvem Final results (opět ji musíme vytvořit v dané úloze).
Následně zkontrolujeme aktuální podobu vztahů na záložce se souhrnnými výsledky po stisku tlačítka Final results:
Správnost provedených kroků zkontrolujeme pomocí tlačítka Ctrl+F9 a výběrem správné položky ze seznamu šablon pro ověření obsahu metabáze:
![]() MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 01 (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 01 (Hotel.MBVC.zip)
![]() MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 02 (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 04 MCluster-Miner 02 (Hotel.MBVC.zip)
Související témata:
