Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Příklad úlohy pro analytickou proceduru a modul ETree-Miner.
Položíme si tuto analytickou otázku:
Přesnost budeme chápat jako kvalitu vytvořeného rozhodovacího stromu na testovacích datech, pro jejíž ověření použijeme křížové ověření (ang. cross-validation). Při generování budeme požadovat 99% čistotu uzlu.
Formálně můžeme otázku zapsat takto:
kde Hotel jsou analyzovaná data, ETree určuje použitou GUHA-proceduru; DHodnoceni je cílový atribut; qcv je použitý způsob testování jako cross-validace s požadovanou mírou 95 %; p udává požadovanou 99% čistotu uzlu; a na závěr je uveden seznam vysvětlujících atributů použitelných při vytváření stromu.
Algoritmus pro vytváření rozhodovacího stromu byl navržen primárně pro diskrétní veličiny. Následně byl rozšířen i na spojité veličiny tak, že se vlastně automaticky binarizují na dva intervaly (menší nebo rovno než daná hodnota × větší než daná hodnota). To i odpovídá způsobu práce s atributy v systému LISp-Miner s tím, že spojité veličiny diskretizujeme na větší množství ekvidistantních intervalů. Budou tak dostatečně jemné (krátké), aby i tak dobře charakterizovaly spojitou veličinu. Ukazuje se, že dostatečný je už počet dvaceti ekvidistantních intervalů.
Následně můžeme buď vytvořit dichotomické atributy ručně, nebo nechat ETree-Miner, aby je za nás vytvářel dynamicky sám.
Pro všechny čtyři sloupce dílčího hodnocení jsme již ve fázi Předzpracování vytvořili několik variant kategorizace na různě dlouhé intervaly. V této ukázce aplikace analytické procedury ETree-Miner použijeme nejprve varianty atributů diskretizované na tři ekvifrekvenční intervaly (_ef3) a následně i varianty s jemnějším dělením na 5 intervalů (_edc5_m) symbolizovaných počtem hvězdiček.
Jednoduchý strom jsem se pokusili vytvořit ručně už v interaktivní analýze. Z praktických důvodů však nebylo možné jít příliš do hloubky a hlavně použít atributy s více než třemi kategoriemi.
Výhodou je, že analytická procedura ETree-Miner za nás bude automaticky generovat i složitější stromy a testovat, jak dobře lze podle nich vyplněné dotazníky klasifikovat.
Před zadáváním úlohy vytvéříme nejprve novou skupinu úloh, kterou pojmenujeme podle analytické otázky, na kterou bude úloha (resp. úlohy) hledat odpověď – v tomto případě 05: Klasifikace dílčích hodnocení.
Číselný prefix 05 v názvu odkazuje na číslo analytické úlohy a zároveň zajistí řazení skupin v seznamu podle analytických otázek.
Nyní již přidáme novou úlohu pro analytickou proceduru ETree-Miner a nazveme ji 05: DHodnoceni: DUbytovani, DStrava, DPersonal, DZabava, aby z jejího názvu bylo jednak patrné, že odpovídá na pátou analytickou otázku, ale i to, jaká je cílová třída a jaké jsou použité atributy.
V základních parametrech úlohy po zadání názvu ještě změníme příslušnost úlohy do skupiny, kterou jsme přidali před chvílí.
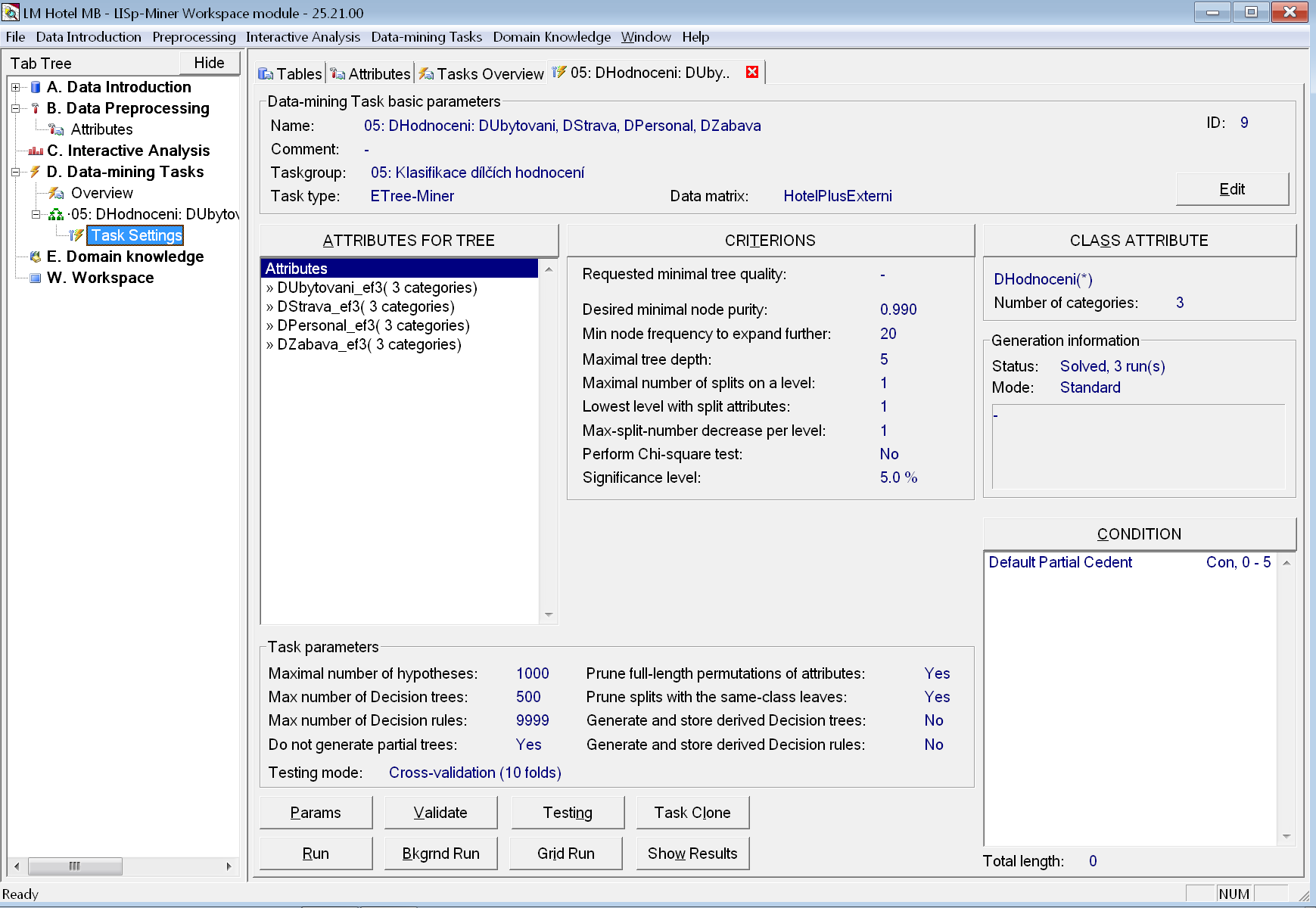
Ukázku úplného zadání úlohy (po provedení všech kroků uvedených níže) vidíme na obrázku.
V seznamu atributů použitelných pro vytváření stromu jsou uvedena všechna dostupná dílčí hodnocení. V tomto případě ve variantě na tři ekvifrekvenční intervaly (_ef3).
Všechny čtyři atributy byly přidány najednou jejich současným označením ve stromu skupin a do nich patřících atributů (pomocí klávesy Ctrl). V zadání parametrů pro první z přidávaných atributů bylo ponecháno výchozí nastavení způsobu binarizace (volba None). Pouze z kosmetických důvodů bylo pořadí atributů změněno pomocí tlačítek Up a Down, aby odpovídalo pořadí dílčích hodnocení v dotazníku a v názvu úlohy.
V parametrech kritérií zatím nezadáváme požadovanou kvalitu stromu, bychom vždy získali alespoň nějaký strom. Dosaženou kvalitu uvidíme ve výsledcích.
Cílovým atributem je v tomto případě DHodnoceni.
Jako způsob testování zvolíme křížovou validaci (cross-validation) na 10 dílů.
Tím je zadání úlohy pro ETree-Miner připraveno.
Před spuštěním výpočtu ověříme tlačítkem Validate, že jsme neopomněli žádnou nezbytnou část zadání. Potom spustíme výpočet tlačítkem Run.
Po skončení výpočtu se výsledky zobrazí na záložce Task Results.
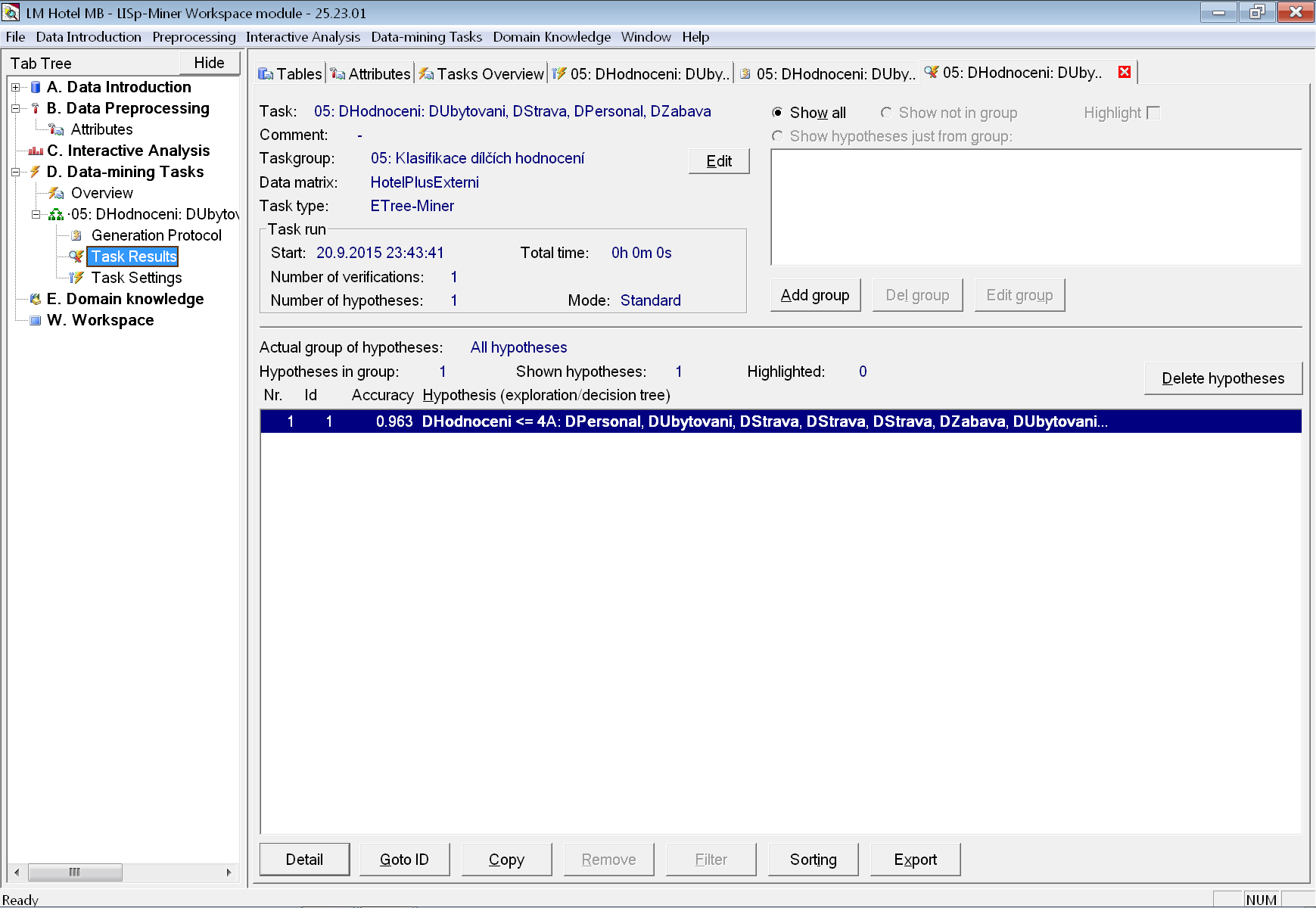
Na obrázku vidíme jeden nalezený rozhodovací strom s dosaženou přesností na trénovacích datech ve výši 96,3 %. Kvalita stromu na trénovacích datech je však velmi nespolehlivým ukazatelem a v podstatě lze říci pouze to, že kvalita v reálu bude spíše horší.
Všimněme si však, že ve stromu otevřených záložek vlevo se objevila i záložka Generation Protocol. Když na ni přepneme, vidíme záznam způsobu generování stromu, který na konci obsahuje i výsledky testování podle zvolené metody (v tomto případě cross-validace).
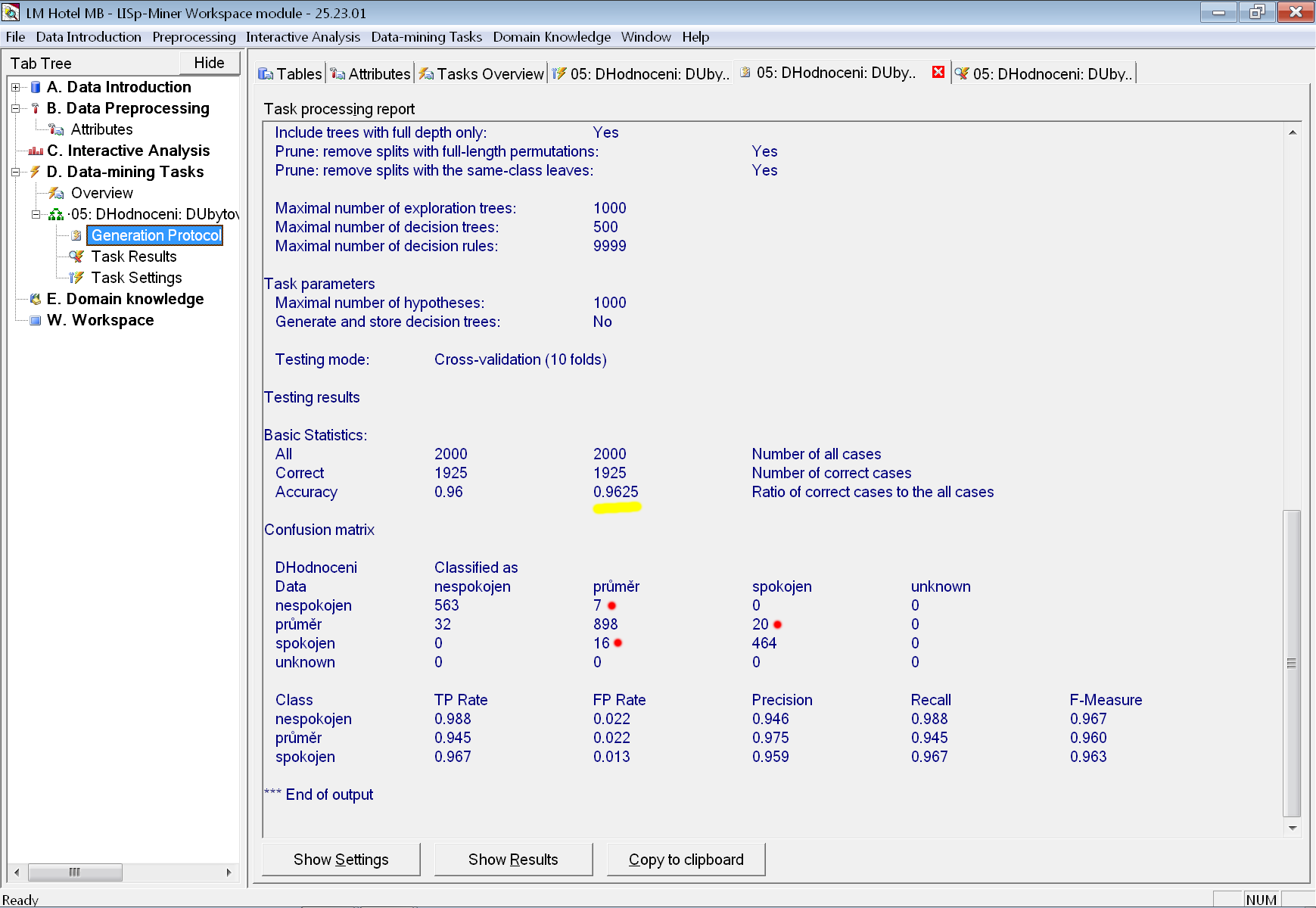
Vidíme, že i na testovacích datech vychází přesnost na 96,3 %. Z vypsané matice záměn (angl. confusion matrix) však vidíme, že strom jako model trochu „nadhodnocuje“ – sedm dotazníků s výsledným hodnocením nespokojen klasifikoval jako průměr a dokonce 20 dotazníků s hodnocením průměr označil jako spokojen (i když na druhou stranu 16 spokojených klasifikoval jako průměr). V doméně Hotel patrně není nadhodnocování v tomto počtu příliš zásadní problém, ale určitě existují domény, ve kterých by jednostranný bias modelu mohl působit značné problémy.
Přepneme se zpět na záložku s výsledky a všimněme si také, že ve výsledcích se nezobrazují sufixy použité pro vyjádření způsobu předzpracování atributů, které by mohly majitele dat mást. Toho jsme docílili zadáním alternativního názvu atributu.
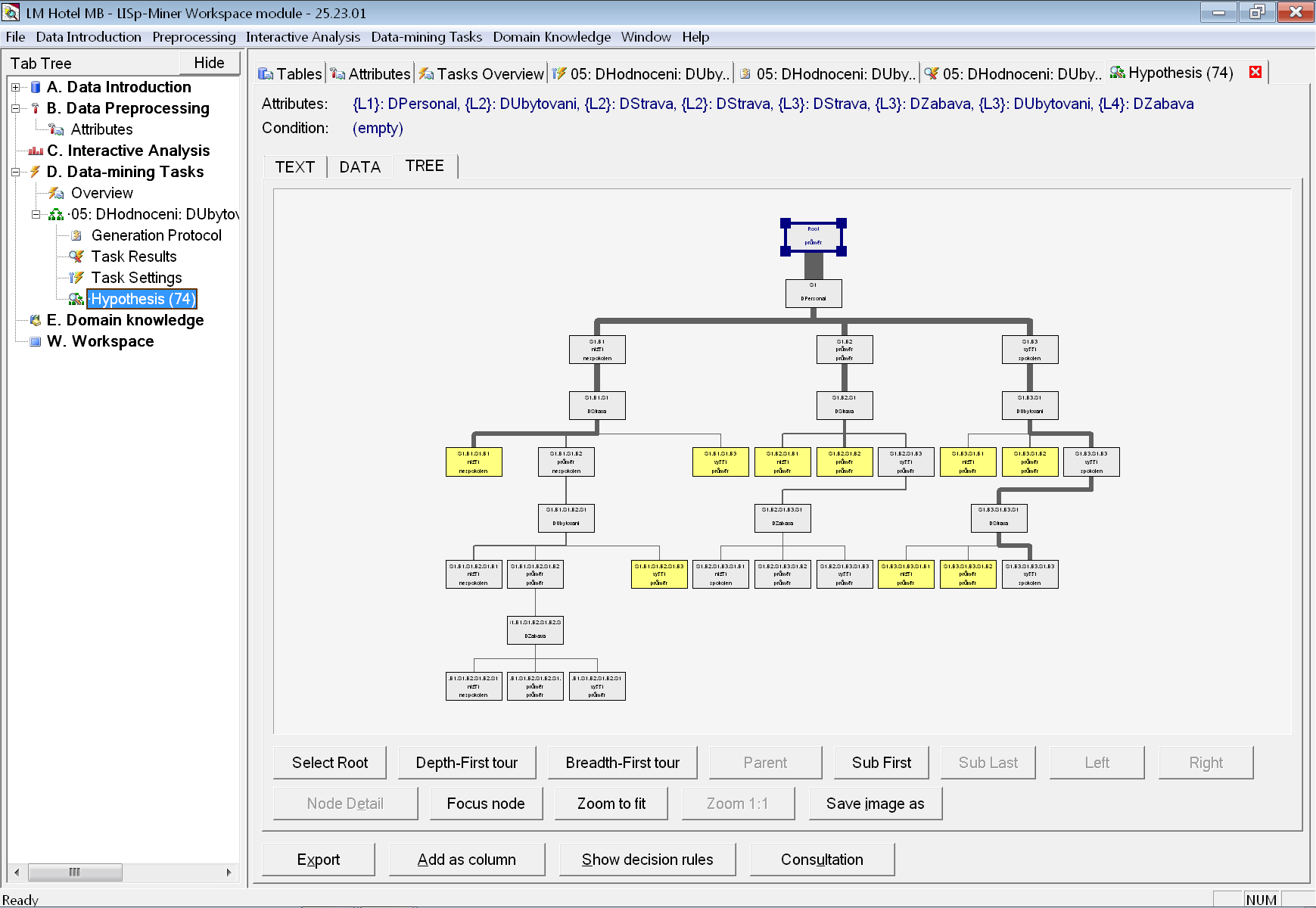
Po otevření záložky s detailem stromu vidíme, že je o trochu složitější, než námi ručně vytvořený strom. Žlutě zvýrazněné listy jsou 100% čisté. U zbylých můžeme jejich čistotu zjistit dvojitým kliknutím na uzel.
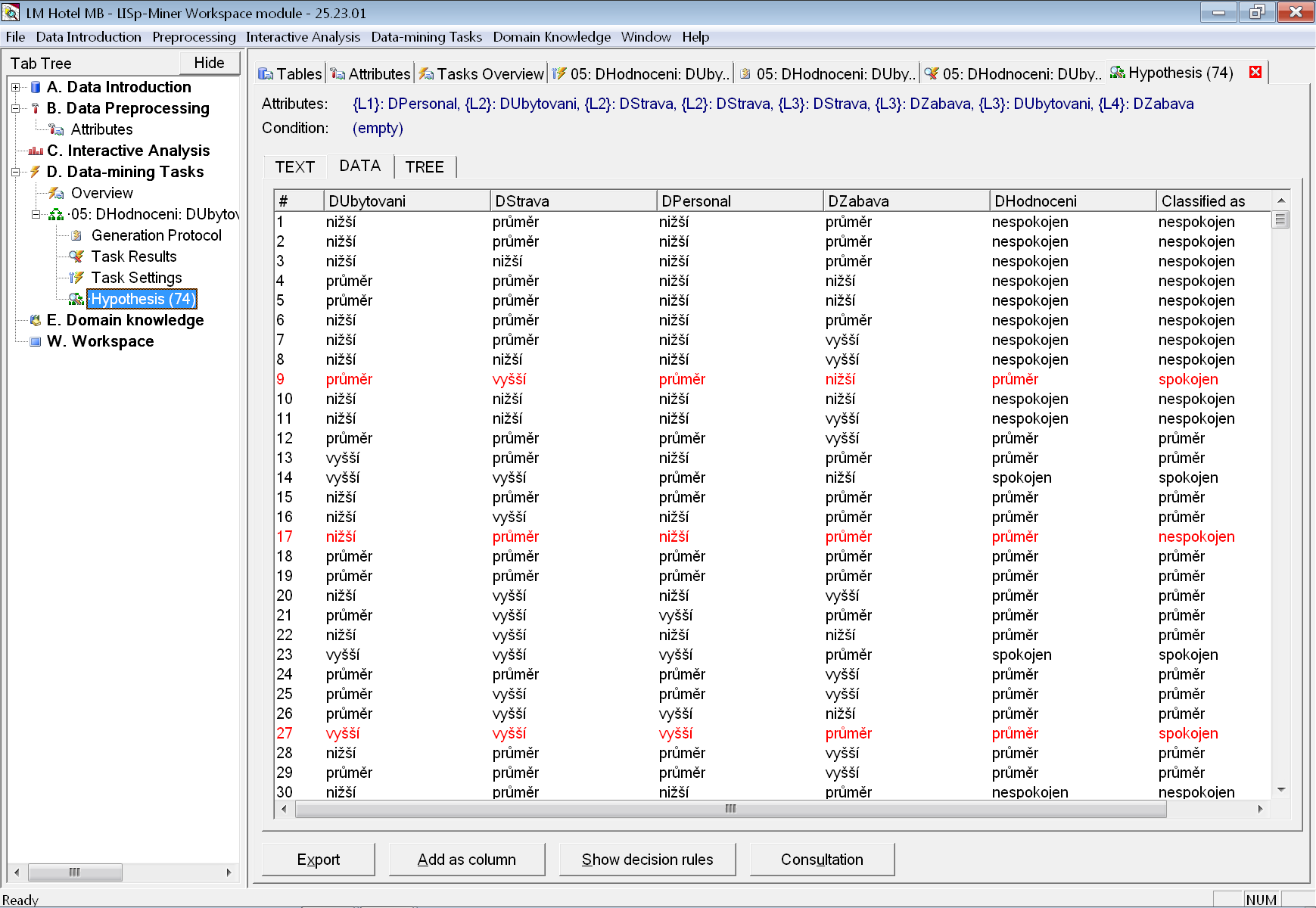
Po přepnutí na dílčí záložku DATA (a potvrzení dotazu na vytvoření rozhodovacích pravidel) získáme podrobný výpis jednotlivých záznamů analyzovaných dat spolu s informací, do jaké třídy byly klasifikovány právě vytvořeným rozhodovacím stromem. Červeně jsou zvýrazněný chybné klasifikace.
Takto vypadající rozhodovací strom nám nevyhovuje, protože je poměrně složitý. Zároveň používá pouze hrubé rozdělení hodnot dílčích hodnocení na tři intervaly. Nešlo by použít jemnější členění? Zároveň platí, že jednodušší model je lepší (snazší na pochopení i robustnější). Proto se pokusíme získat strom jednodušší, aniž by se (výrazně) zhoršila jeho kvalita.
![]() MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (Hotel.MBVC.zip)
Přepneme se na záložku s detaily zadání úlohy a nejprve vytvoříme její klon. Nové úloze ponecháme přednastavený název 05: DHodnoceni: DUbytovani, DStrava, DPersonal, DZabava (01).
Nyní použijeme varianty atributů s pěti ekvidistantními intervaly přejmenované na hvězdičky (s koncovkou _edc5_m) a zároveň budeme vytvářet binární strom. Pro snazší zapamatování si podrobnější vysvětlení způsobu zadání můžeme zapsat do poznámky úlohy.
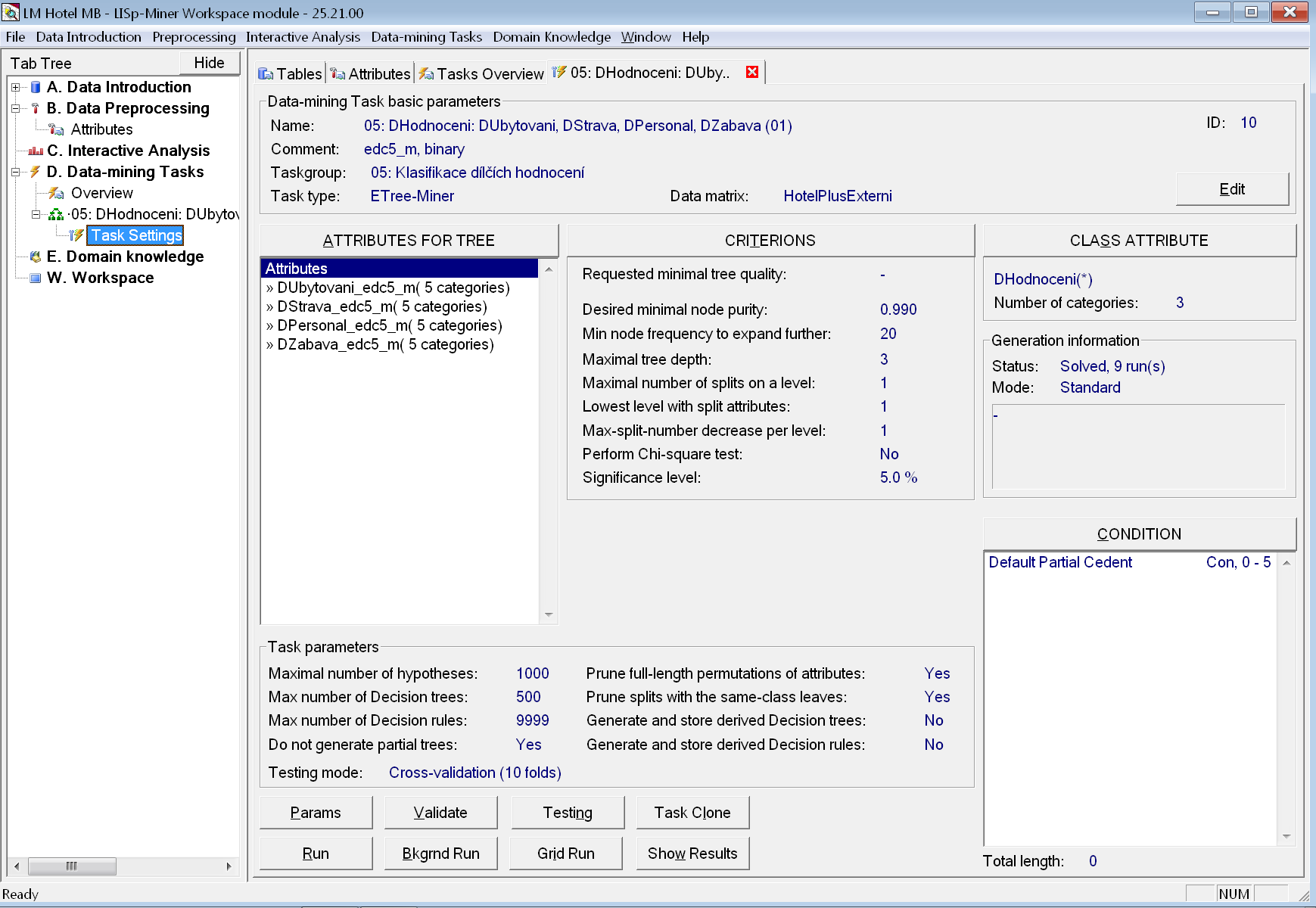
V seznam atributů pro vytváření stromu nahradíme atributy s koncovkou _ef3 za atributy s koncovkou _edc5_m. To snadno uděláme označením všech původních atributů a jejich odstraněním pomocí tlačítka Del. Následně přidáme opět najednou všechny nové atributy.
Protože nové atributy mají každý pět kategorií, byl by vytvořený strom velmi „košatý“ (počet větví vycházejích z uzlu odpovídá počtu kategorií atributu použitého pro větvení) a pravděpodobně málo robustní. Využijeme tedy možnost automatické binarizace, kdy z daného uzlu budou vycházet vždy jen dvě větve – větev pro hodnoty „menší nebo rovny než daná hodnota“ a větev pro hodnoty „vyšší než daná hodnota“.
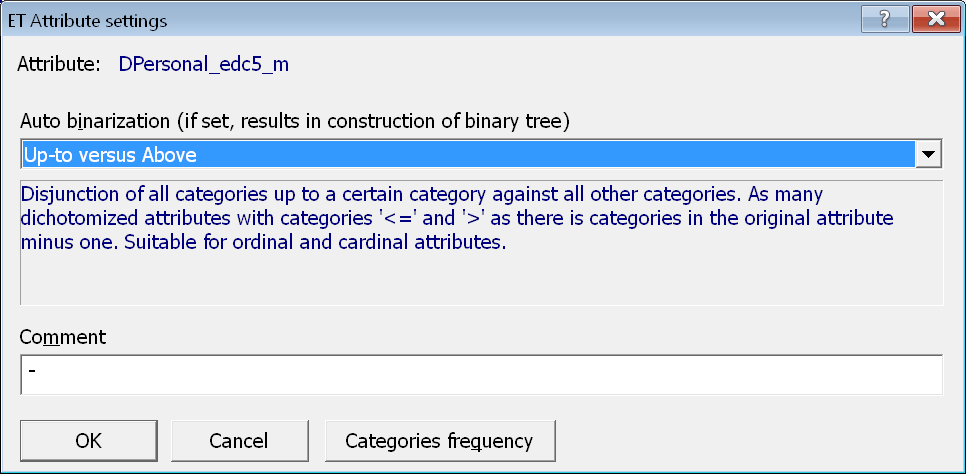
Jde o standardní způsob zacházení s atributy o mnoha kategoriích, a proto LISp-Miner pro ně nabídne automatickou binarizaci sám. V případě, že by místo ordinálních hodnot byly vkládány nominální atributy, byl by použit druhý způsob binarizace.
Po hromadném přidání atributů ještě upravíme pořadí pomocí tlačítek Up a Down (opět jen z kosmetických důvodů).
Binární stromy bývají hlubší, než stromy používající pro větvení atributy s více kategoriemi. Maximální hloubku stromu můžeme ovlivnit stejnojmenným parametrem v dialogovém okně vyvolaném tlačítkem CRITERIONS. V tomto případě je nastavíme na 3, aby byl stromu opravdu jednoduchý.
Po spuštění a skončení výpočtu se výsledky zobrazí na záložce Task Results.
Opět byl nalezen jeden strom, ale jeho kvalita je dokonce 99,3 % (na trénovacích datech). Při použití cross-validace (na záložce Generation Protocol) je kvalita také 99,3 %.
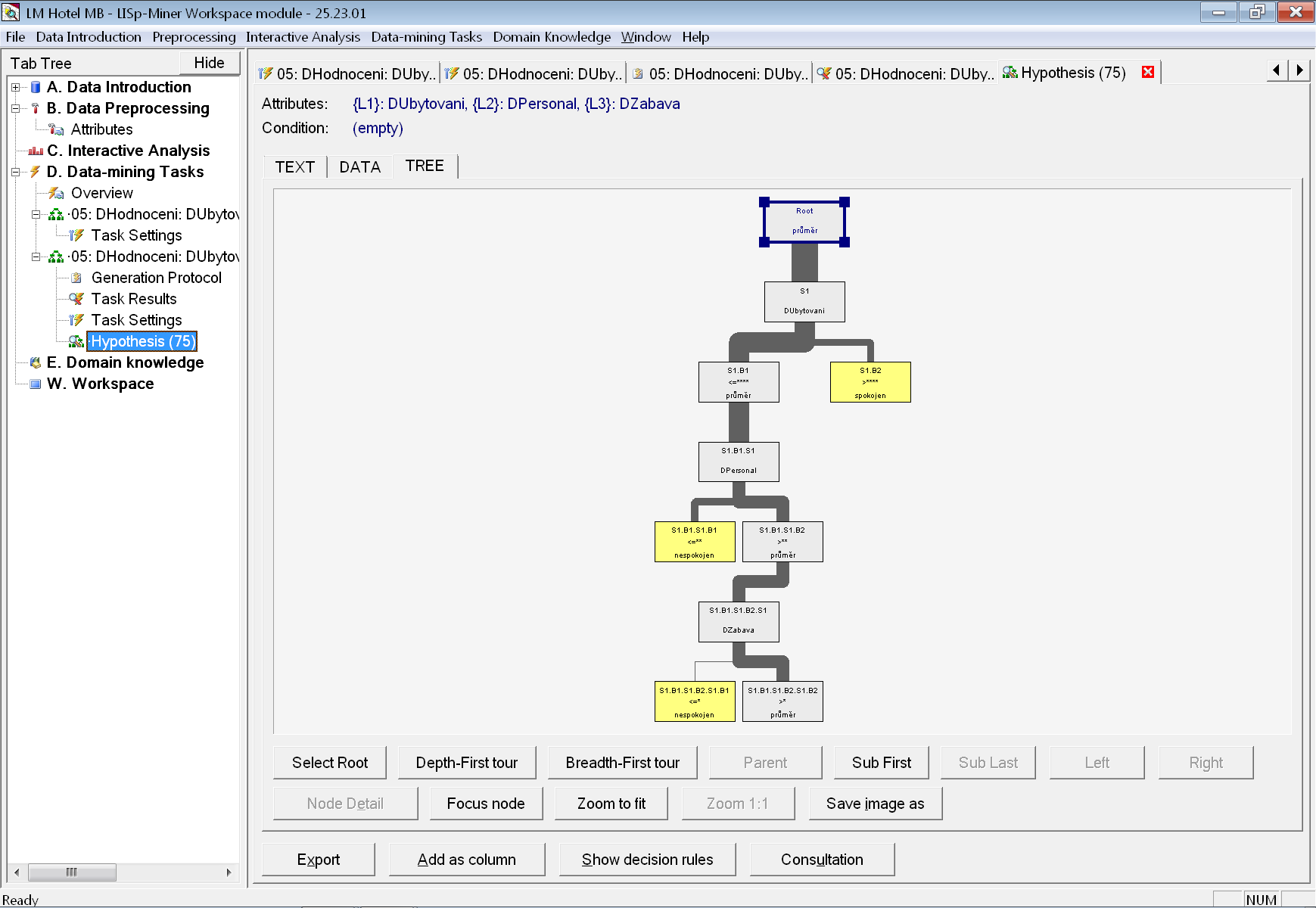
Po otevření záložky s detailem stromu vidíme na záložce TREE, že i samotný strom je jednodušší. Ke klasifikace potřebuje tři atributy – DUbytovani, DPersonal a DZabava.
Tím jsme splnili cíl nalézt jednodušší strom, aniž by došlo ke zhoršení jeho kvality (ta je dokonce lepší).
![]() MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (01) (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (01) (Hotel.MBVC.zip)
Nalezený rozhodovací strom můžeme pomocí tlačítka Show decision rules převést na čtyři jednoduchá rozhodovací pravidla, která mu jsou ekvivalentní.
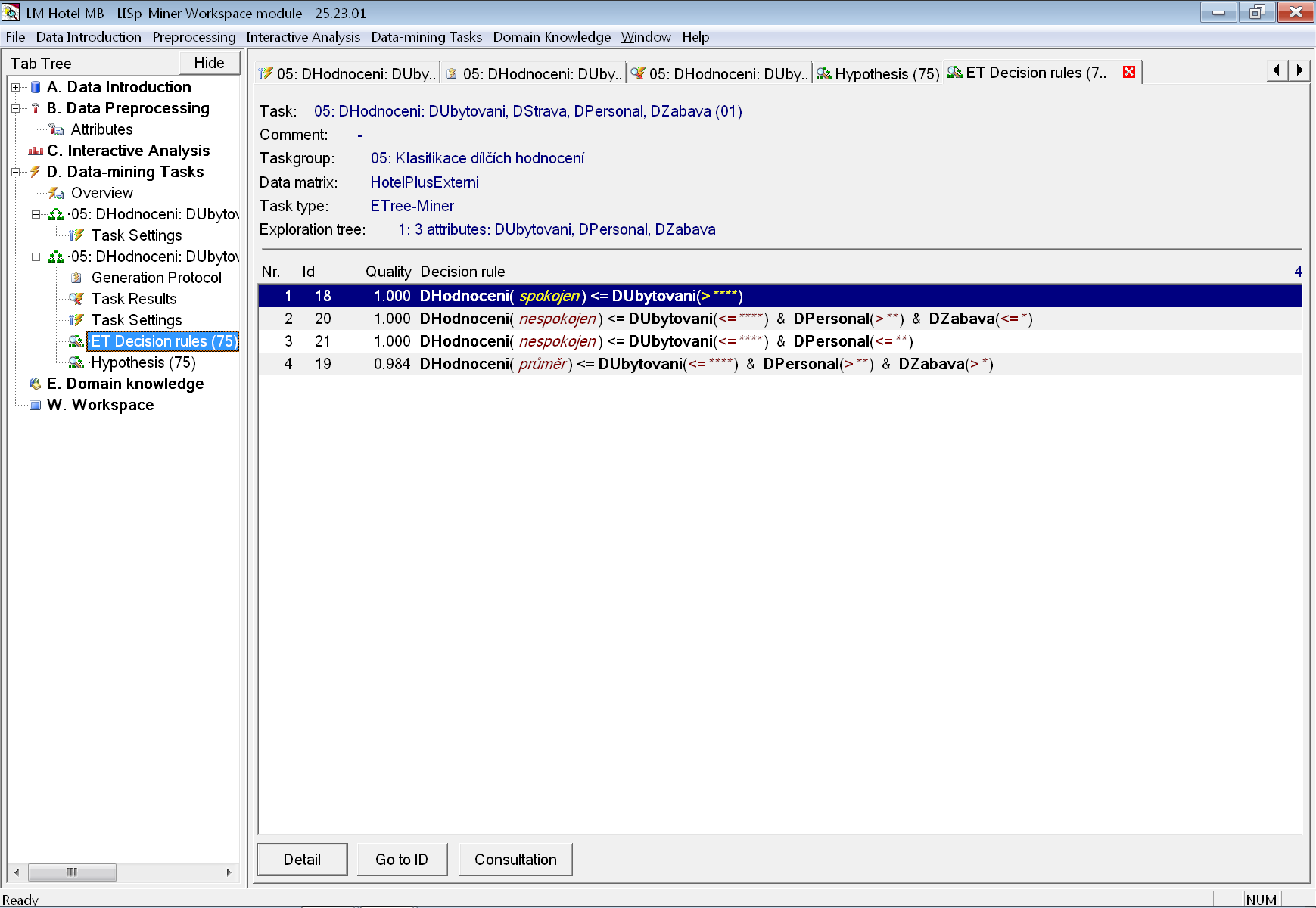
Odpověď na položenou analytickou zní: „Na základě hodnot dílčích hodnocení lze pomocí rozhodovacího stromu určit s přesností na cca 99 % celkové hodnocení v dotazníku.“
Díky použité funkci klonování máme ve skupině „05: Klasifikace dílčích hodnocení“ záznam řešení páté analytické otázky.
Ze dvou získaných rozhodovacích stromů zvolíme druhý, protože dosahuje lepší přesnosti na testovacích datech. I v případě, že by kvalita obou modelů byla přibližně stejné, tak bychom zvolili druhý, protože je jednodušší, a tím pádem i robustnější a praktičtější.
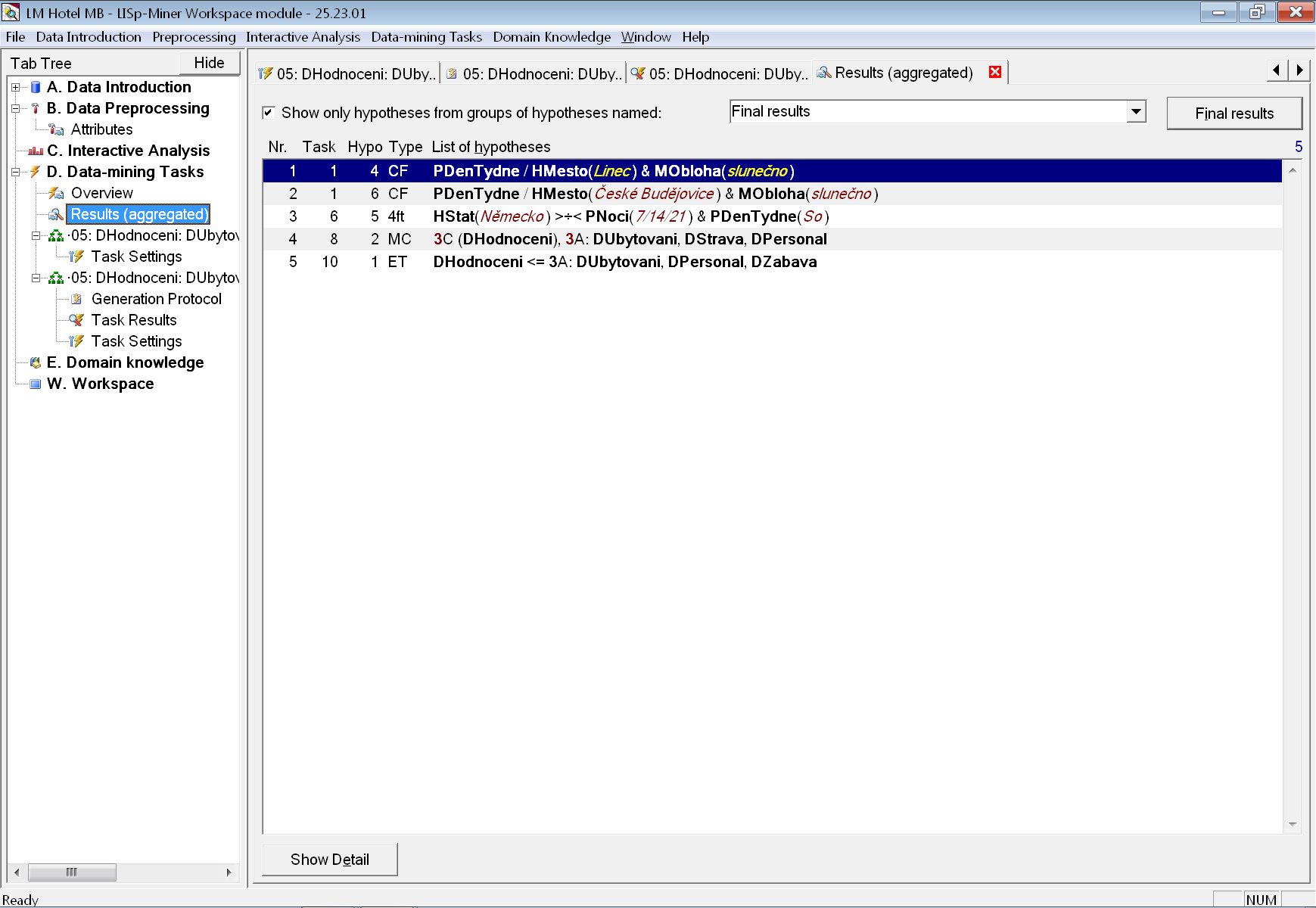
Rozhodovací strom nalezený v druhé úloze proto přesuneme pomocí tlačítka Copy do skupiny hypotéz Final results (opět ji musíme vytvořit v dané úloze).
Následně zkontrolujeme aktuální podobu vztahů na záložce se souhrnnými výsledky po stisku tlačítka Final results:
Správnost provedených kroků zkontrolujeme pomocí tlačítka Ctrl+F9 a výběrem správné položky ze seznamu šablon pro ověření obsahu metabáze:
![]() MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (Hotel.MBVC.zip)
![]() MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (01) (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 05 ETree-Miner (01) (Hotel.MBVC.zip)
Související témata:
