Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Příklad úlohy pro analytickou proceduru a modul KL-Miner.
Položíme si tuto analytickou otázku:
Oba použité atributy jsou kardinální. Proto budeme závislost definovat ve smyslu Kendallova koeficientu pořadové korelace (τb) a začneme s velmi silnou korelací ve výši alespoň 0,9. Přitom nám nevadí, jestli jde o silnou pozitivní, nebo silnou negativní korelaci.
Formálně můžeme otázku zapsat takto:
kde Hotel jsou analyzovaná data, KL určuje použitou GUHA-proceduru, TauB ≥ 0,9 je zápis použitého KL-kvantifikátoru, HVek je atribut, jehož kategorie mají být v řádcích kontingenční tabulky, PCenaCelkem je atribut, jehož kategorie mají být ve sloupcích kontingenční tabulky, a na závěr je uveden seznam skupin atributů použitelných pro generování variant podmnožin dat.
Oba atributy pro konstrukci kontingenční tabulky by měly mít vhodný počet kategorií. Určitě by jich mělo být více než dvě (v opačném případě bývá obvykle lepší použít 4ft-Miner). Na zvážení je maximální počet kategorií. Vhodný počet bude záviset například i na tom, aby vzniklá kontingenční tabulka byla dobře čitelná.
V této úloze vybereme variantu věku s expertním rozdělením na čtyři kategorie (HVek_exp) a variantu celkové ceny s ekvifrekvenčními intervaly o počtu 5 (PCenaCelkem_ef5).
Abychom měli lepší představu o existenci či neexistenci zkoumané závislosti na celých datech, provedeme rychlou interaktivní kontingenční analýzu obou atributů. Tím budeme schopni i lépe posoudit, které z později získaných výsledků analytické procedury jsou zajímavé.
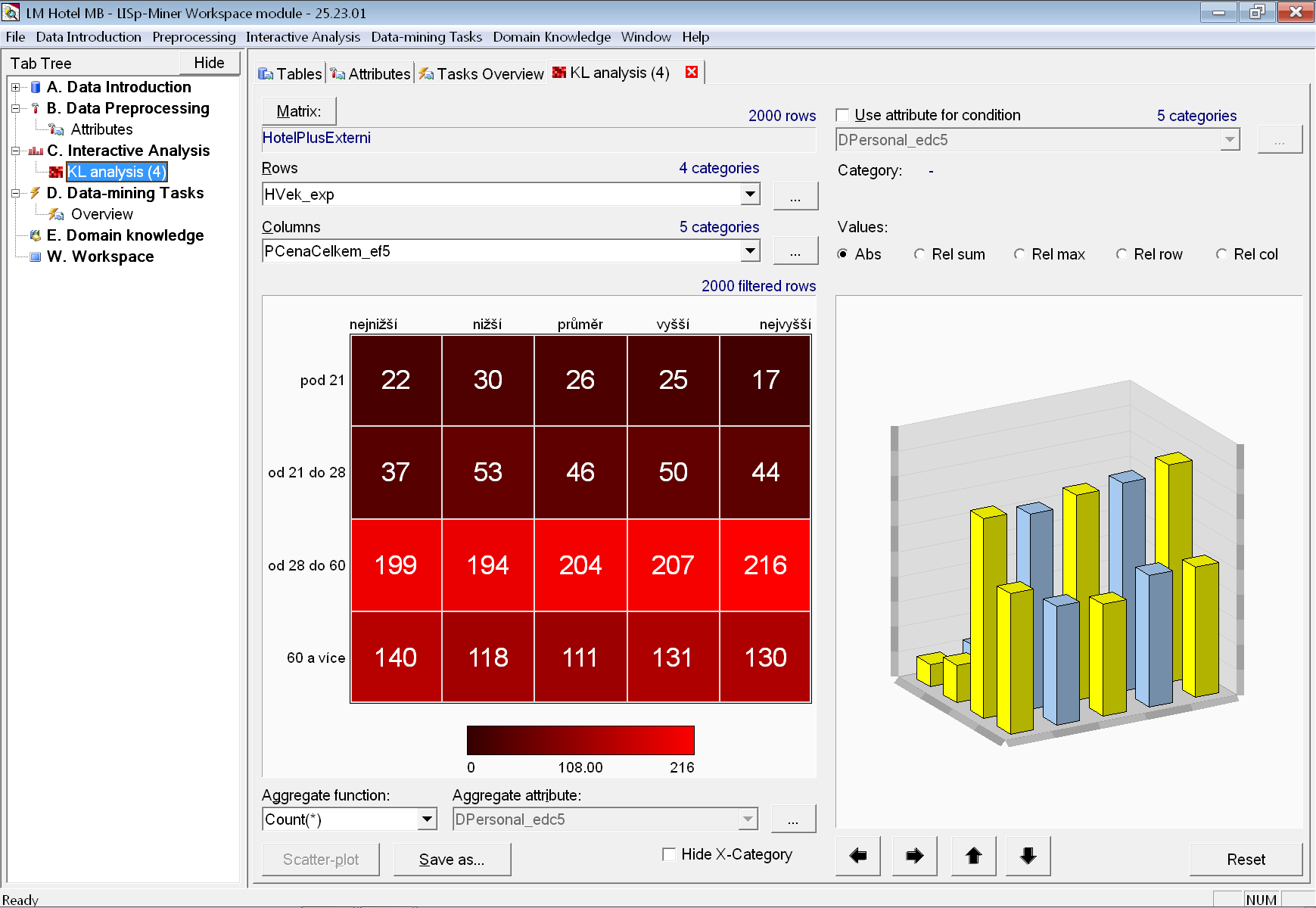
Z kontingenční tabulky není patrná nějaká výrazná závislost mezi oběma atributy. Bude nás tedy zajímat, jestli se taková závislost neobjeví pro nějakou vhodně vybranou podmnožinu pobytů.
Výhodou je, že analytická procedura KL-Miner bude za nás automaticky a systematicky procházet všechny možné takové podmnožiny a testovat, zda pro v nich zmíněná závislost platí, či nikoliv.
Před zadáváním úlohy opět nejprve vytvoříme novou skupinu úloh, kterou pojmenujeme podle analytické otázky, na kterou bude úloha hledat odpověď – v tomto případě 02: Závislost mezi věkem hosta a celkovou cenou pobytu.
Číselný prefix 02 v názvu odkazuje na číslo analytické úlohy a zároveň zajistí řazení skupin v seznamu podle analytických otázek.
Nyní již přidáme novou úlohu pro analytickou proceduru KL-Miner a nazveme ji 02: HVek x PCenaCelkem / Bydliště, Pobyt, aby z jejího názvu bylo jednak opět patrné, že odpovídá na druhou analytickou otázku, ale i to, jaké jsou použity atributy pro řádky a sloupce kontingenční tabulky a dále skupiny atributů pro generování variant podmnožin dat.
V základních parametrech úlohy po zadání názvu ještě změníme příslušnost úlohy do skupiny, kterou jsme přidali před chvílí.
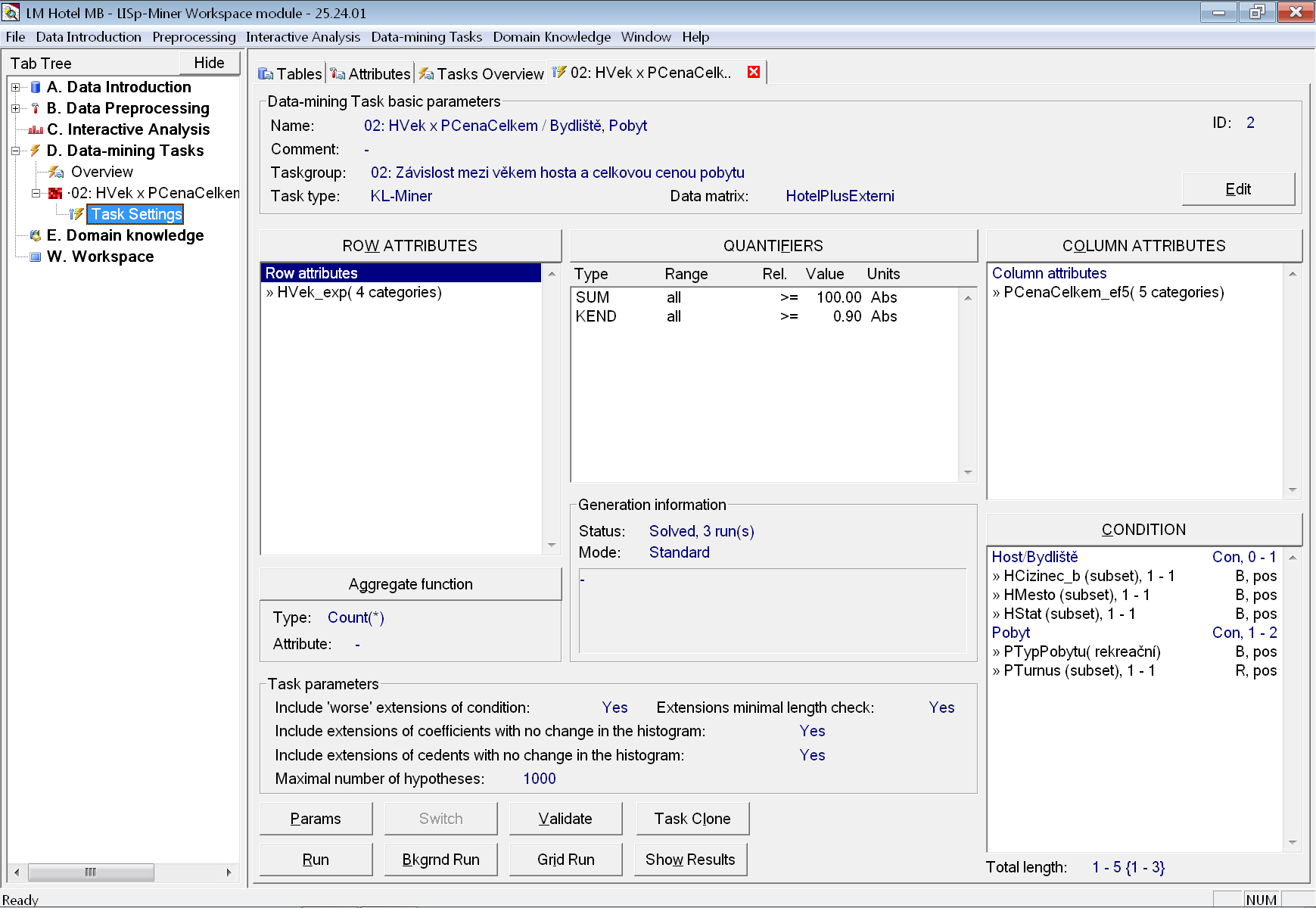
Ukázku úplného zadání úlohy (po provedení všech kroků uvedených níže) vidíme na obrázku.
Do seznamu atributů pro řádky byl vložen atribut HVek_exp, do seznamu atributů pro sloupce pak atribut PCenaCelkem_ef5.
Jedná se o typický způsob zadání úlohy pro KL-Miner. Do seznamů je sice možné zadat atributů více, ale výsledky úlohy potom obsahují celou řadu různých kontingenčních tabulek a pro zodpovězení většiny formulovaných analytických otázek jsou nepřehledné.
Účelem KL-kvantifikátorů je popsat, jaké hodnoty četností v kontingenční tabulce považujeme vzhledem k formulované analytické otázce za zajímavé.
V tomto případě požadujeme hodnotu Kendallova koeficientu pořadové korelace (τb) alespoň ve výši 0,9. V dialogovém okně vyvolaném tlačítkem QUANTIFIERS stiskneme Add statistical quantifier a výše definovaný požadavek zadáme pomocí výběru správné míry zajímavosti (Kendall's TauB coefficient), operace porovnání (Greater than or equal) a zadáním prahové hodnoty (0,9).
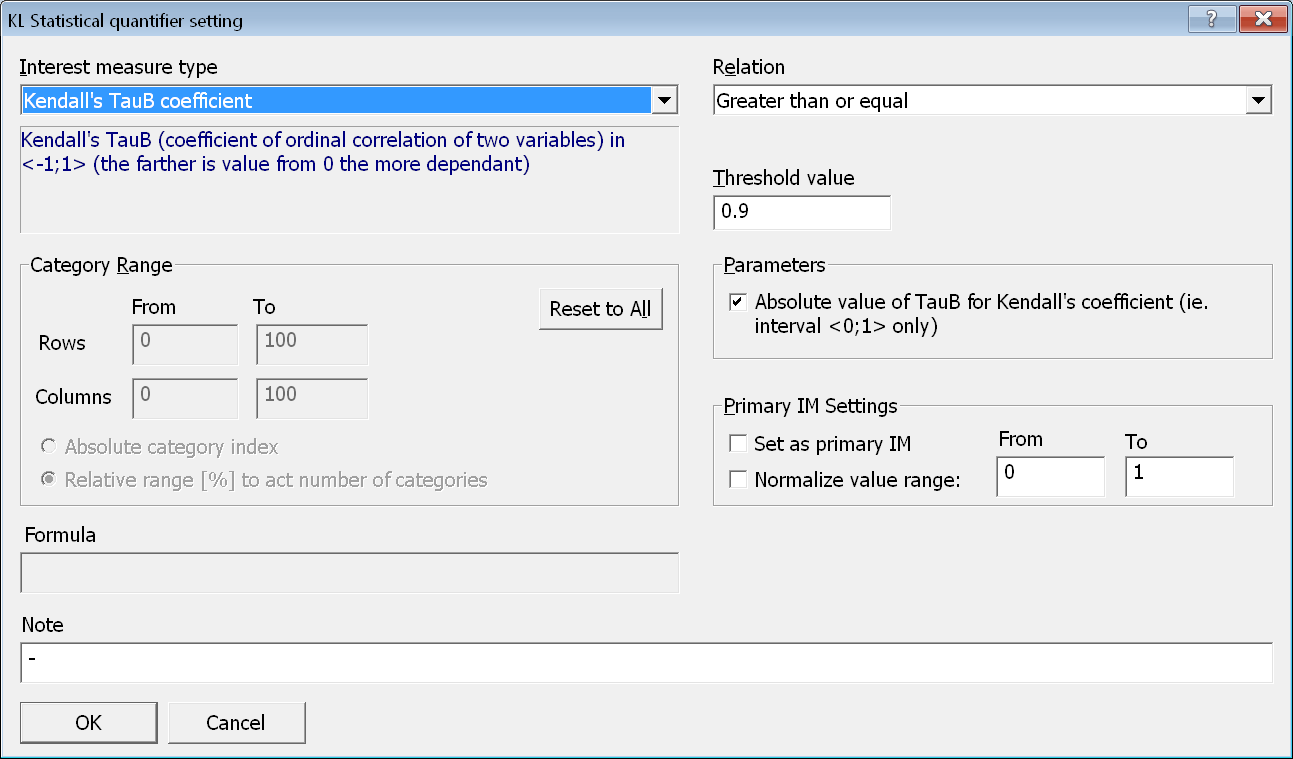
Protože se podmnožiny dat budou generovat jako všechny možné kombinace údajů o bydlišti hosta a o pobytu, tak je vhodné zajistit, že právě vygenerovaná podmnožina je dostatečně četná, aby na ní vůbec mělo smysl kontingenční tabulku počítat. To zajistíme pomocí dalšího KL-kvantifikátoru (tentokrát jednoduchého frekvenčního) s mírou zajímavosti Sum of frequencies a vhodnou prahovou hodnotou.
KL-kvantifikátor tohoto typu je součástí téměř všech zadání úlohu, a proto se objeví automaticky v každé nově přidané úloze pro KL-Miner. Přednastavená prahová hodnota je 20, což je naprosté minimum a obvykle bude nutné ji zvýšit. V této ukázce zkusíme zvýšit na 100.
Podmnožiny dat budeme chtít generovat pro všechny možné kombinace atributů dvou skupin – Host/Bydliště a Pobyt. V této ukázce nebudeme pro zjednoduššení vkládat úplně všechny atributy. Z první skupiny vybereme pouze atributy HCizinec_b, HMesto a HStat a ze skupiny Pobyt pouze atributy PTypPobytu a PTurnus.
Protože jsme už dílčí cedent pro skupinu Host/Bydliště zadávali při řešení první analytické otázky v úloze pro CF-Miner, nemusíme jej zadávat celý znovu. V dialogovém okně pro zadání cedentů použijeme tlačítko Import a celé zadání dílčího cedentu zkopírujeme do právě vytvářeného zadání podmínky. Tím se zkopíruje i nastavení minimální a maximální délky dílčího cedentu.
Druhý dílčí cedent s atributy ze skupiny Pobyt musíme zadat ručně. Využíváme možnosti popsané v zadání množiny relevantních cedentů.
Analýzu chceme omezit pouze na rekreační pobyty, a proto v zadání literálu pro atribut PTypPobytu zvolíme typ koeficientu One category a vybereme kategorii rekreační.
V zadání literálu pro atribut PTurnus ponecháme typ koeficientu Subset. Naopak však zadáme typ literálu jako Remaining. To bude mít spolu se zadanou minimální a maximální délkou dílčího cedentu Pobyt jako 1 až 2 za efekt, že v generováných variantách pomnožiny dat bude vždy jeden atribut z tohoto dílčího cedentu a tímto atributem bude PTypPobytu (je označen jako Basic). Atribut PTurnus může být až jako druhý, dodatečný atribut.
Nesmíme zapomenout ještě opravit minimální a maximální délku celé podmínky. Minimální délka podmínky byla zvýšena na 1, aby se negenerovala „prázdná“ podmínka a kontingenční tabulka se tak nepočítala na celých datech.
Před spuštěním výpočtu ověříme tlačítkem Validate, že jsme neopomněli žádnou nezbytnou část zadání. Potom spustíme výpočet tlačítkem Run.
Po skončení výpočtu se zobrazí záložka Task Results. Bohužel však zjistíme, že seznam nalezených vztahů je prázdný. V datech totiž nebyla nalezena žádná taková podmnožina dat z daných kombinací atributů, pro kterou by kontingenční tabulka splňovala kritéria zadaných kvantifikátorů.
To je běžný jev při analýze dat. Musíme se vrátit do zadání úlohy a pokusit se je pozměnit tak, aby se už něco našlo. Nabízí se dvě možnosti – zmírnit kritérií kvantifikátorů, nebo zvýšit počet generovaných podmínek a tím zvýšit šance, že pro některou z nich budou kritéria splněna. Případně můžeme provést obě změny najednou, ale obvykle bývá lepší dělat změny postupně, aby vždy bylo zřejmé, k jakým změnám v zadání úlohy došlo.
Dejme tomu, že se rozhodneme pro první variantu – zmírnění kritérií kvantifikátorů. V našem případě půjde o nastavenou prahovou hodnotu Kendallova koeficientu. Místo, abychom postupně zkoušeli hodnoty 0.8, 0.7, 0.6 atd., použijeme tlačítko Validate k zobrazení doporučeného intervalu:
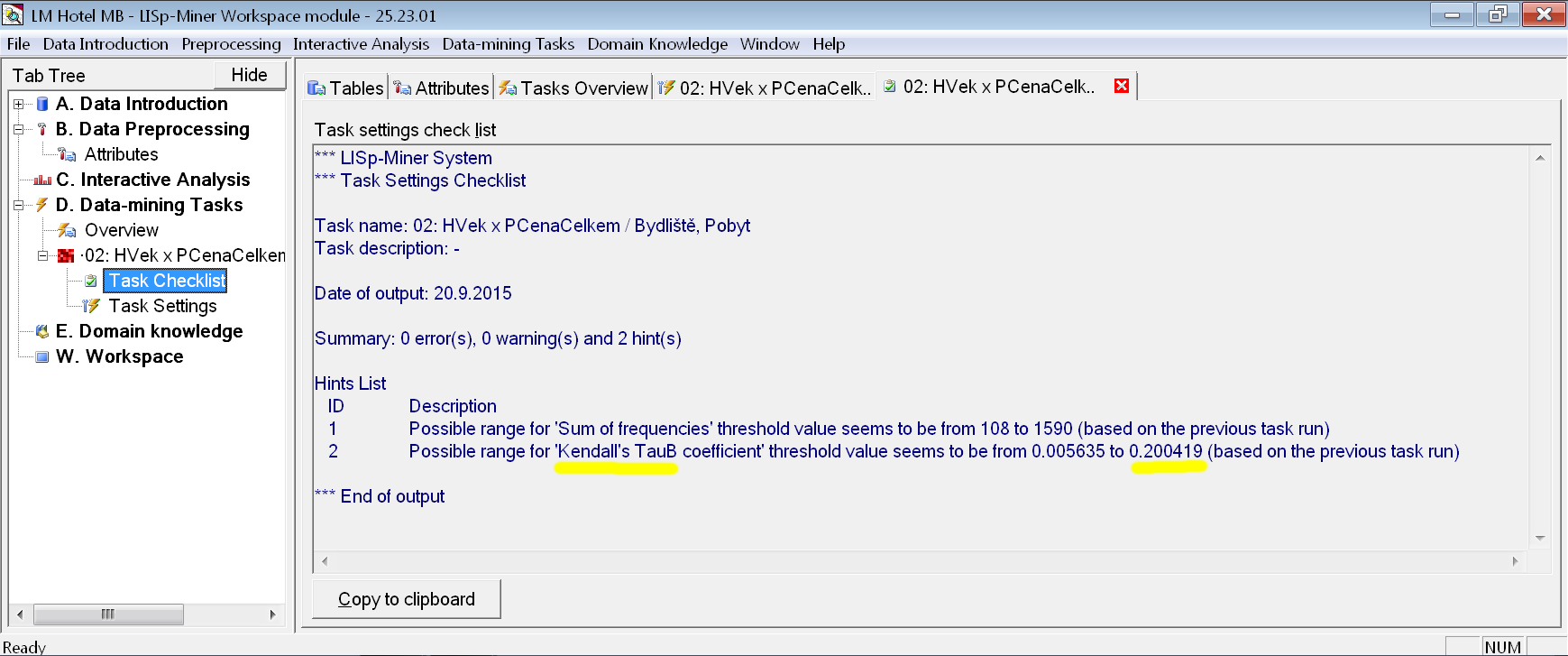
Vidíme, že prahová hodnota musí klesnout až pod 0,20. Pouze potom budou v datech nalezeny alespoň nějaké vztahy. To je však již velmi nízká hodnota Kendallova koeficientu, takže v praxi bychom asi už ani nepokračovali dále. Pro výukové účely však zadání úlohy upravíme.
Před tím však můžeme ověřit správnost zadání úlohy:
![]() MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (Hotel.MBVC.zip)
Na záložce s detaily zadání úlohy vytvoříme klon úlohy. Nové úloze ponecháme přednastavený název „02: HVek x PCenaCelkem / Bydliště, Pobyt (01)“. Do poznámky můžeme uvést, že v této úloze snížíme práh kvantifikátoru pro Kendallův koeficient.
Následně změníme práh kvantifikátoru pro Kendallův koeficient na hodnotu 0,2 a spustíme výpočet úlohy.
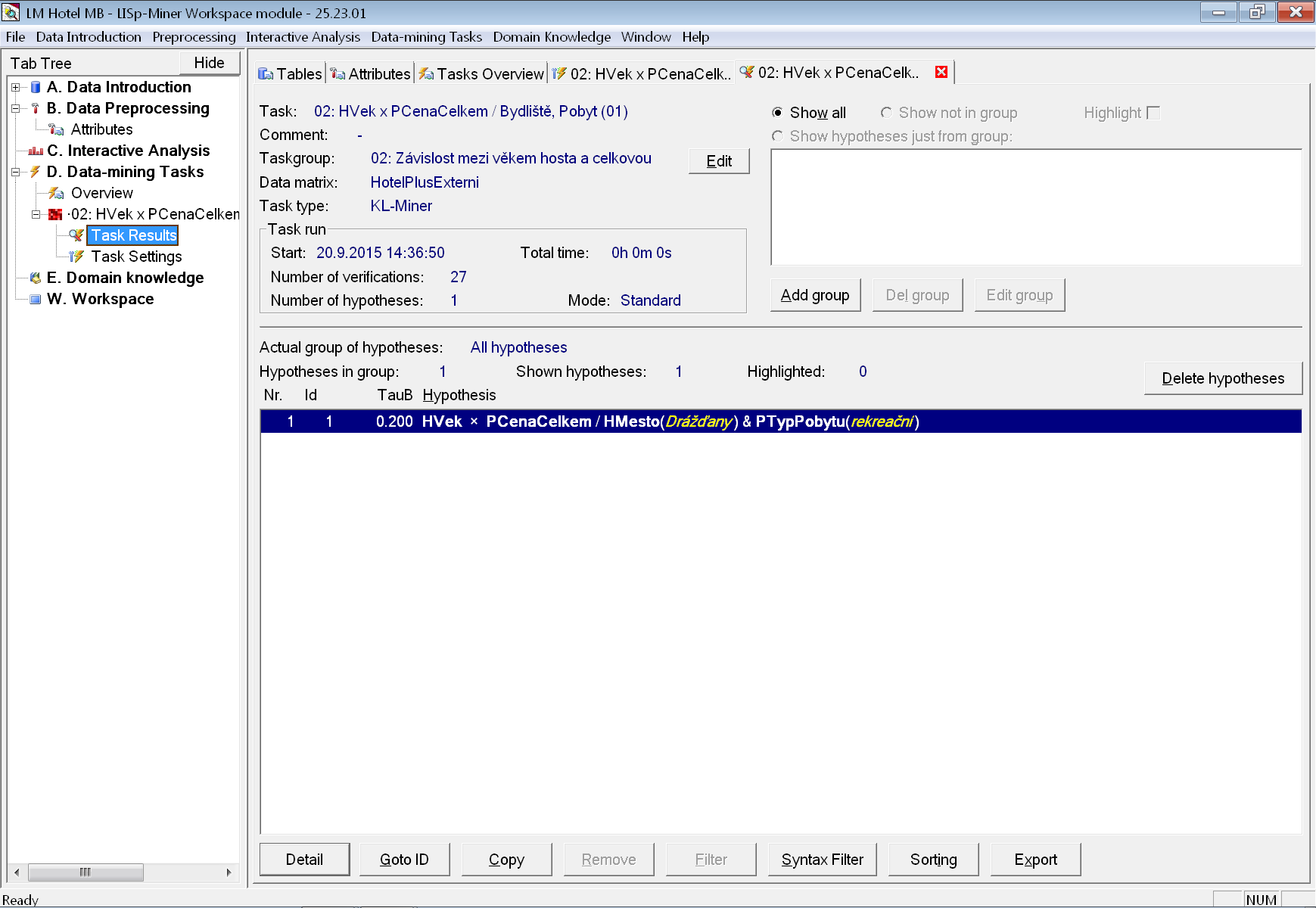
Tentokrát už vidíme alespoň jeden nalezený KL-vztah pro reakreační pobyty hostů z Drážďan.
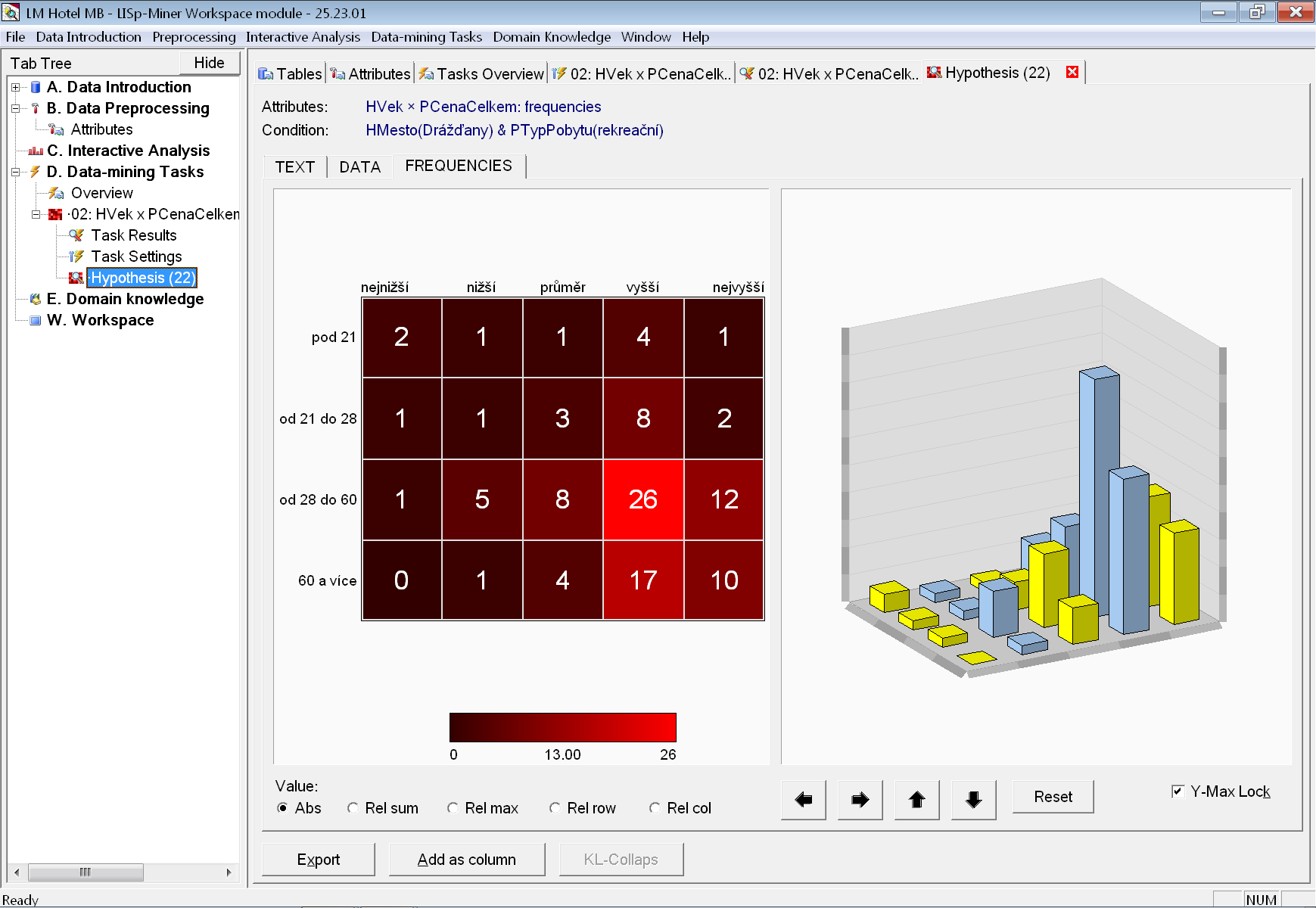
Otevřemi si záložku s detailem a vidíme, že pořadová závislost kategorií obou atributů je opravdu velmi slabá.
Všimněme si také, že ve výsledcích se nezobrazují sufixy použité pro vyjádření způsobu předzpracování atributů, které by mohly majitele dat mást. Toho jsme docílili zadáním alternativního názvu atributu.
![]() MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (01) (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (01) (Hotel.MBVC.zip)
Odpověď na druhou analytickou otázku tedy zní „Ani v celých datech, ani na některé jejich podmnožině definované kombinací vybraných atributů ze skupin Host/Bydliště a Pobyt se nepodařilo nalézt silnější korelaci ve smyslu Kendallova koeficientu pořadové korelace (τb).“
Ve vytvořené skupině 02: Závislost mezi věkem hosta a celkovou cenou pobytu pro zodpovězení druhé analytické otázky máme zaznamenám postup řešení v podobě dvou úloh.
U první úlohy nebyly nalezeny žádný vztahy. U druhé úlohy došlo ke snížení prahu a nalezení dvou vztahů, které však jsou velmi slabé a v praxi patrně nevyužitelné.
Žádný z nalezených vztahů nezařadíme mezi nejvýznamnější výsledky analýzy.
Správnost provedených kroků zkontrolujeme pomocí tlačítka Ctrl+F9 a výběrem správné položky ze seznamu šablon pro ověření obsahu metabáze:
![]() MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (Hotel.MBVC.zip)
![]() MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (01) (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 02 KL-Miner (01) (Hotel.MBVC.zip)
Související témata:
