Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Zejména pro účely výuky byla do systému LISp-Miner implementována funkce pro ověření uživatelem správně zadaných definic pro analýzu – zejména způsobu načtení dat, způsobu jejich předzpracování a zadání úloh.
Ověřování kontroluje shodu metabáze s nějakou dříve připravenou ověřovací šablonou.
Ověřování postupuje podle fází DZD od činností pro seznámení s daty (zejména jejich načtení do systému), přes předzpracování dat (vytvoření stromu skupin a do nich patřících atributů), až po zadání úloh a získané výsledky. V každé fázi jsou vypisovány závažné chyby a méně závažná varování vyplývající z nesouladu mezi aktuálním a očekávaným stavem metabáze.
Příkladem použití jsou ověřovací šablony připravené pro jednotlivé kroky komplexní ukázky Demo Hotel: Úvodní přehledový postup analýzy.
Dialogové okno pro ověření obsahu metabáze vyvoláme buď z menu File/Metabase content verification, nebo pohodlněji pomocí klávesové zkratky Ctrl+F9. Klávesová zkratka navíc funguje kdekoliv v modulu LM Workspace.
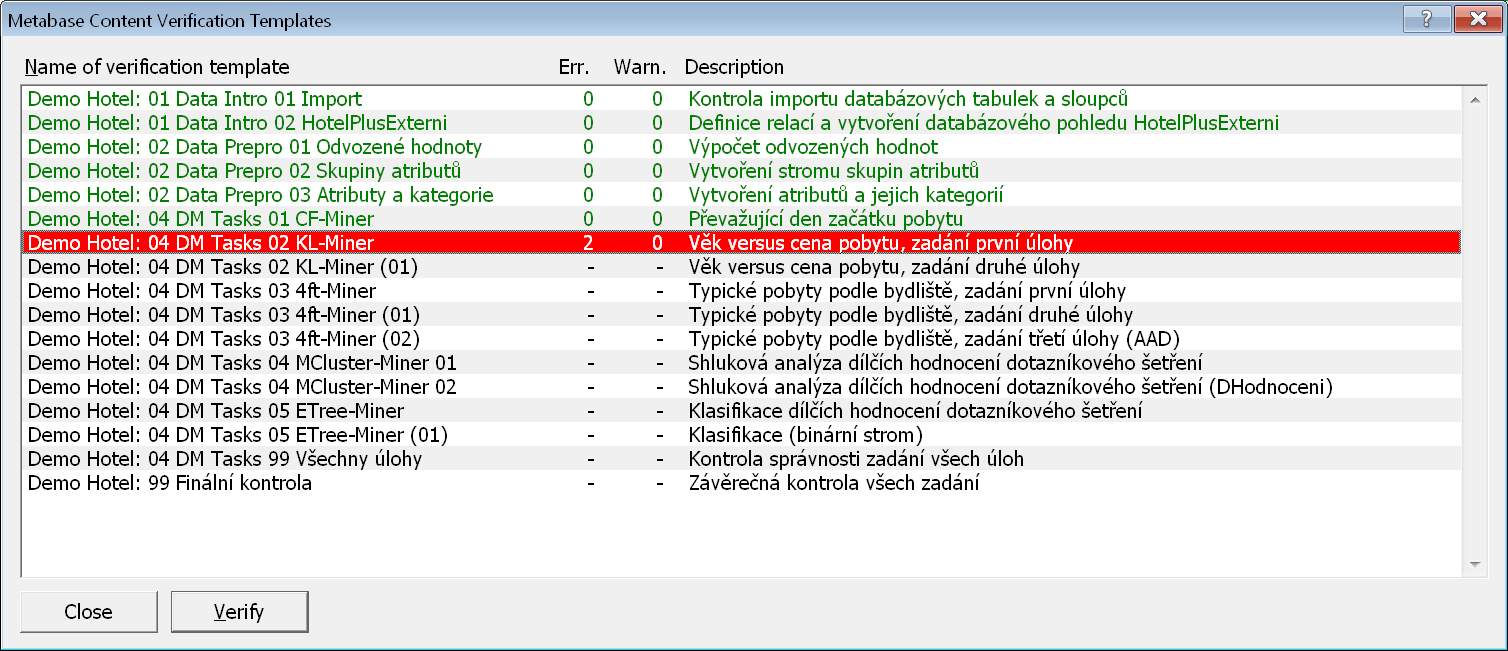
Na obrázku vidíme seznam ověřovacích šablon pro Demo Hotel: Úvodní přehledový postup analýzy. Pro již spuštěná ověřování vidíme i počet nalezených chyb a varování.
Po výběru jedné z šablon (podle kroku, ve kterém se právě nacházíme) a stisknutí tlačítka Verify se spustí ověřování, jehož výsledkem je textová zpráva.
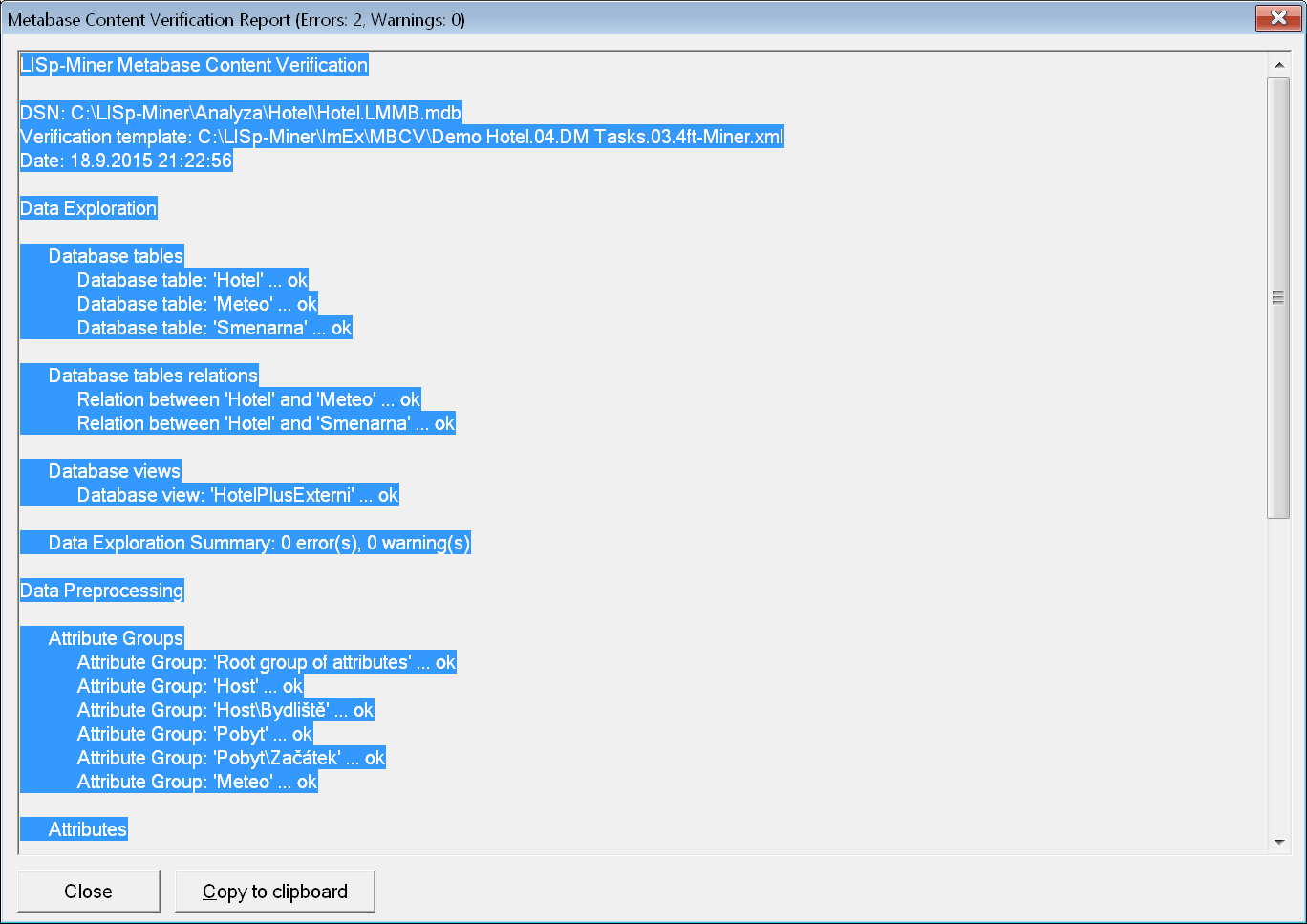
Pro každou z fází je uveden počet nalezených chyb a varování. Na závěr zprávy je pak celkový součet. Celkový počet chyb a varování je pro rychlé a snadné zjištění zobrazen i v titulku dialogového okna zprávy.
Cílem je dosáhnout nulového celkového počtu chyb i varování.
Automatické ověření obsahu metabáze je poměrně obtížná úloha. Proto může být v některých případech správné zadání označeno za chybné, nebo vydáno varování.
Zejména je třeba nezpanikařit, když se po prvním spuštění ověření podle nějaké šablony objeví například 100 chyb. S největší pravděpodobností bude velká část z nich navzájem provázaná a způsobená například špatně nastavenou počáteční levou mezí ekvidistantních intervalů. Pokud je v atributu 50 kategorií, tak máme hned 50 chyb. Jednoduchou opravou počáteční meze a přegenerováním intervalů máme rázem o polovinu chyb méně.
Dále je třeba dát pozor na:
