Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Různé typy generovaných koeficientů jsou jednou z možností, která odlišuje LISp-Miner od jiných systémů. V hledaných vztazích totiž nemusí být pouze jedna hodnota z databázového sloupce (jak je obvyklé), ale libovolná (neprázdná) podmnožina kategorií definovaných v rámci předzpracování atributu. Tuto podmnožinu nazýváme koeficient. Zároveň mějme na paměti, že i samotná kategorie může zahrnovat více než jednu původní hodnotu z databázového sloupce.
Hlavní síla je však ve způsobu kombinace více kategorií do koeficientu. Rozeznáváme typy generovaných koeficientů:
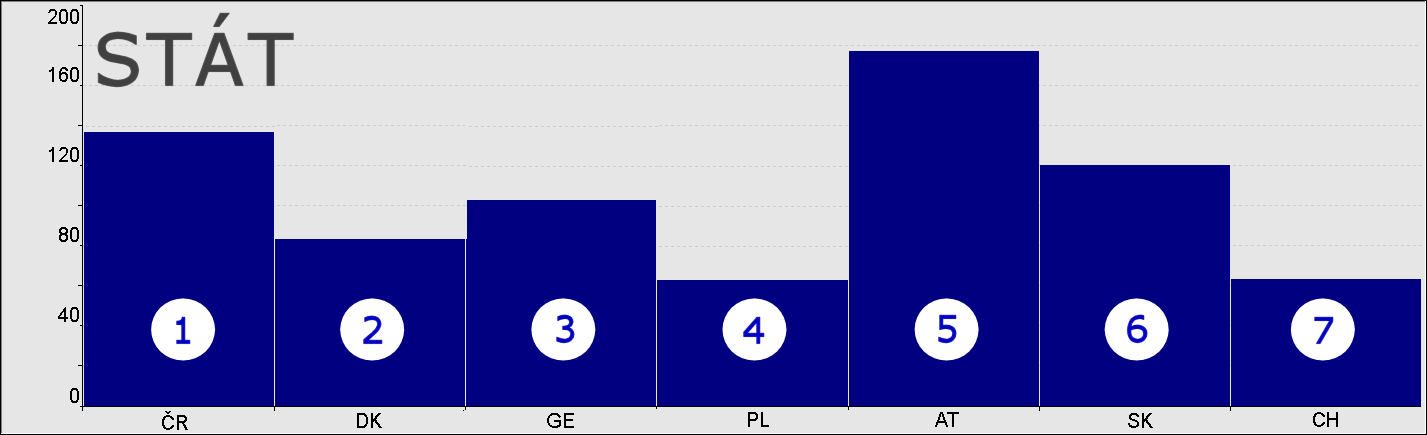 Mějme atribut HStat představující stát, ze kterého host přijel – Česká republika (CR), Dánsko (DK), Německo (GE), Polsko (PL), Rakousko (AT), Slovensko (SK) a Švýcarsko (CH).
Mějme atribut HStat představující stát, ze kterého host přijel – Česká republika (CR), Dánsko (DK), Německo (GE), Polsko (PL), Rakousko (AT), Slovensko (SK) a Švýcarsko (CH).
Na následujícím obrázku vlevo vidíme všechny možné podmnožiny délky jedna. Jejich počet odpovídá počtu kategorií atributu. To není nijak složité.

Na obrázku vpravo vidíme všechny podmnožiny délky dva. Těch je už více. Pro atributy s větším počtem kategorií a delšími podmnožiny může počet generovaných koeficientů narůstat do astronomických výšek.
Zadáme-li rozpětí povolené minimální a maximální délky koeficientů (např. od 1 do 3) budou se postupně generovat všechny jednočlenné, dvoučlenné a tříčlenné podmnožiny kategorií.
Při zadávání koeficientu typu podmnožina je třeba dát pozor na kombinatorickou složitost a používat zejména omezení maximální délky koeficientu (případně i délky dílčího a celého cedentu).
Je třeba mít na paměti i to, že celková velikost množiny relevantních cedentů bude záležit i na počtu možných kombinací ostatních literálů.
Nevhodným zadáním koeficientu typy podmnožina můžeme opravdu značně prodloužit dobu výpočtu úlohy. V extrémních případech by výpočet neskočil do konce trvání světa. Vždy je třeba si položit otázku – „Má vůbec cenu generovat podmnožiny až takové délky?“ Před příliš dlouhými koeficienty typu podmnožina a z toho vyplývajícím rizikem příliš dlouhé doby výpočtu budeme varování při kontrole zadání úlohy, resp. při kontrole zadání cedentu.
Počet možných variant kombinací kategorií vypočteme jako kombinační číslo a závisí na počtu kategorií celkem (n) a počtu vybíraných (k):
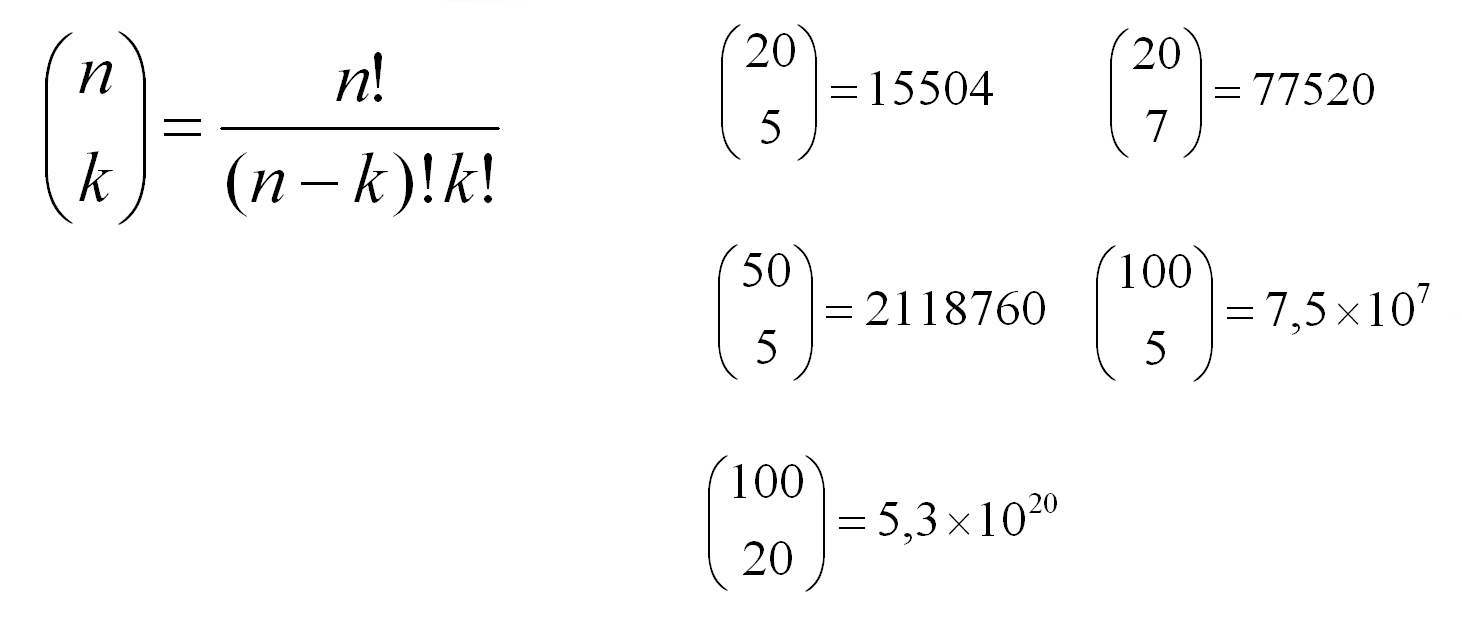
Vidíme, že i pro relativně „malý“ atribut se sto kategoriemi, by po zadání generování všech podmnožin délky 20 bylo tolik variant, že bychom se výsledku nedočkali.
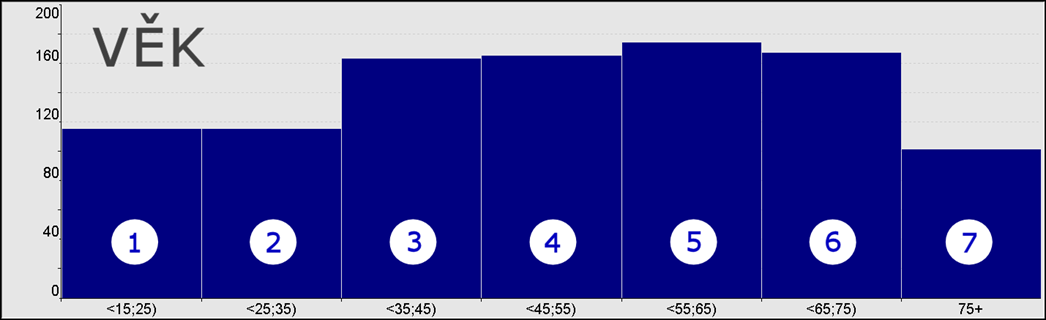 Mějme atribut HVek popisující věk hosta jako ekvidistantní intervaly o délce 10. Všimněme si tedy, že jedna kategorie už sama o sobě zahrnuje více hodnot z databázového sloupce HVek patřících do daného intervalu.
Mějme atribut HVek popisující věk hosta jako ekvidistantní intervaly o délce 10. Všimněme si tedy, že jedna kategorie už sama o sobě zahrnuje více hodnot z databázového sloupce HVek patřících do daného intervalu.
Na následujícím obrázku vlevo vidíme všechny možné posloupnosti délky jedna. Ty jsou shodné jako všechny podmnožiny délky jedna a jejich počet opět odpovídá počtu kategorií atributu.

Uprostřed a vpravo pak vidíme posloupnosti délky dvě a tři. Všimněme si, že se vždy spojují sousední kategorie a při generování po kategoriích postupuje „plovoucí okno“.
Typ koeficientu posloupnost má smysl použít pouze pro ordinální atributy. Doporučená maximální délka koeficientu je do 1/3 počtu kategorií. Počet generovaných variant je roven počtu kategorií mínus délka koeficientu plus jedna.
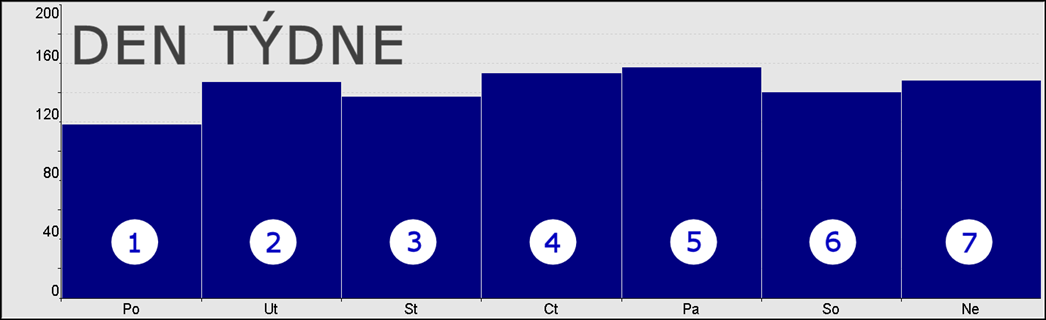 Použít cyklické posloupnosti má smysl tehdy, pokud je atribut nejen ordinální, ale navíc za poslední kategorií následuje opět první. Mějme tedy opět atribut PDenTydne představující dny v týdnu, kde opravdu platí, že po neděli následuje opět pondělí.
Použít cyklické posloupnosti má smysl tehdy, pokud je atribut nejen ordinální, ale navíc za poslední kategorií následuje opět první. Mějme tedy opět atribut PDenTydne představující dny v týdnu, kde opravdu platí, že po neděli následuje opět pondělí.
V případě délky jedna, je opět shodné s podmnožinou a posloupností.
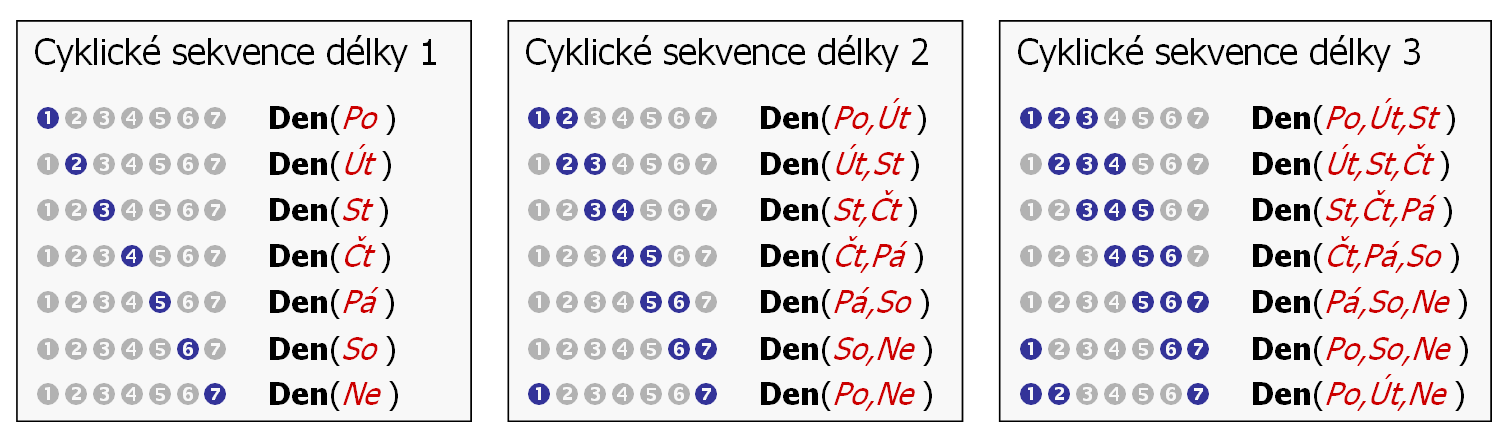
Uprostřed a vpravo však vidíme, že oproti posloupnosti přibyly další kombinace. Počet generovaných variant je roven počtu kategorií.
Koeficient typu jedna kategorie umožňuje ručně nastavit jednu konkrétní kategorii. Délka koeficientu i počet kombinací je vždy jedna.
Tento typ keoficientu se používá pro zacílení analýzy pouze na určitou podmnožinu záznamů – např. pouze na hosty ze Slovenska – HStat(Slovensko), pouze na nespokojené hosty – DHodnoceni(nespokojen) atd.
Snadno se také definuje i komplementární podmnožina, a to zadáním koeficientu jedna kategorie a nastavení typu gace literálu na negative – např. všichni hosté kromě těch ze Slovenska: ¬HStat(Slovensko).
Řezy se hodí pro zkoumání extrémních hodnot atributu – levé řezy pro zkoumání nízkých hodnot, pravé řezy pro zkoumání vysokých hodnot.
Použití obou typů řezů dává smysl pouze pro ordinální atributy. Zadání koeficientu typu řezy postupně generuje nejprve levé řezy, a pak pravé řezy.
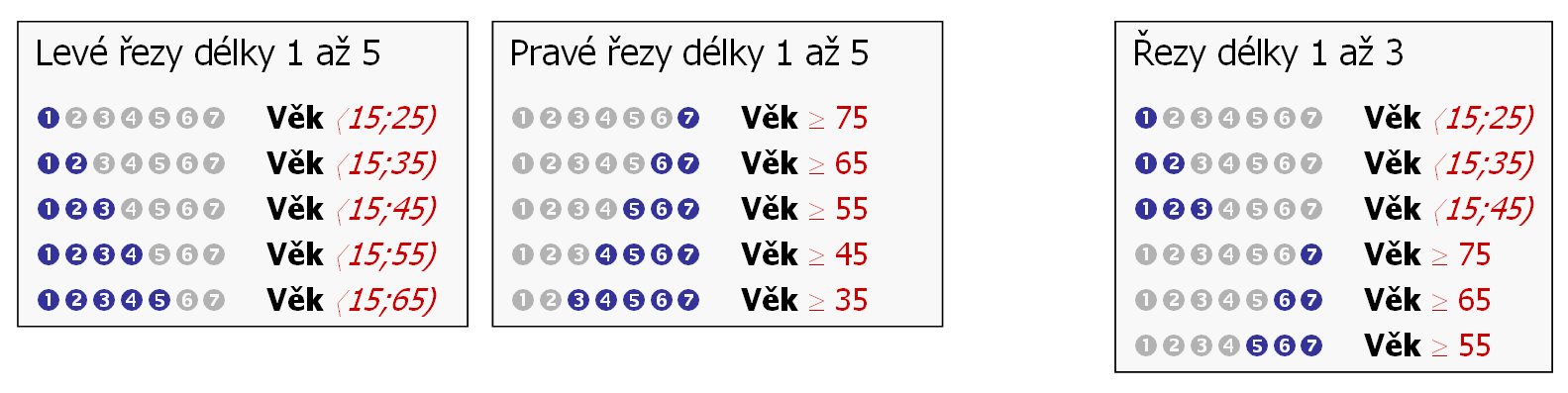
Levé řezy jsou jako posloupnosti dané délky, které však začínají na první kategorii daného atributu. Hodí se pro hledání odpovědí na otázky typu „Do jaké až hodnoty platí, že…?“
Pravé řezy jsou jako posloupnosti dané délky, které však končí na poslední kategorii daného atributu. Hodí se pro hledání odpovědí na otázky typu „Od jaké hodnoty už platí, že…?“
Související témata:
![]() Atribut a jeho kategorie
Atribut a jeho kategorie
![]() Zadání literálu
Zadání literálu
![]() Zadání dílčího cedentu
Zadání dílčího cedentu
![]() Zadání cedentu
Zadání cedentu
![]() Zadání množiny relevantních cedentů
Zadání množiny relevantních cedentů
![]() Zadání úlohy
Zadání úlohy
![]() Kontrola zadání úlohy
Kontrola zadání úlohy
