Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
![]() Funkce pro interaktivní analýzu nabízí další možnosti pro bližší seznámení s daty. Nejde o data-mingovou analýzu v pravém slova smyslu, protože při interaktivní analýze zkoušíme různé pohledy na data a omezení zkoumané množiny ručně. Svoji povahou je podobná OLAP-analýze. Analytické úlohy naproti tomu automaticky prověřují miliony a miliardy různých kombinací na základě námi připraveného zadání.
Funkce pro interaktivní analýzu nabízí další možnosti pro bližší seznámení s daty. Nejde o data-mingovou analýzu v pravém slova smyslu, protože při interaktivní analýze zkoušíme různé pohledy na data a omezení zkoumané množiny ručně. Svoji povahou je podobná OLAP-analýze. Analytické úlohy naproti tomu automaticky prověřují miliony a miliardy různých kombinací na základě námi připraveného zadání.
Smyslem interaktivní analýzy je blíže data poznat a zejména se nechat inspirovat pro formulaci analytických otázek a zadávání analytických úloh.
Příkladem využití Scatter-plot analýzy je zobrazení závislosti mezi dnem začátku pobytu a teplotou.
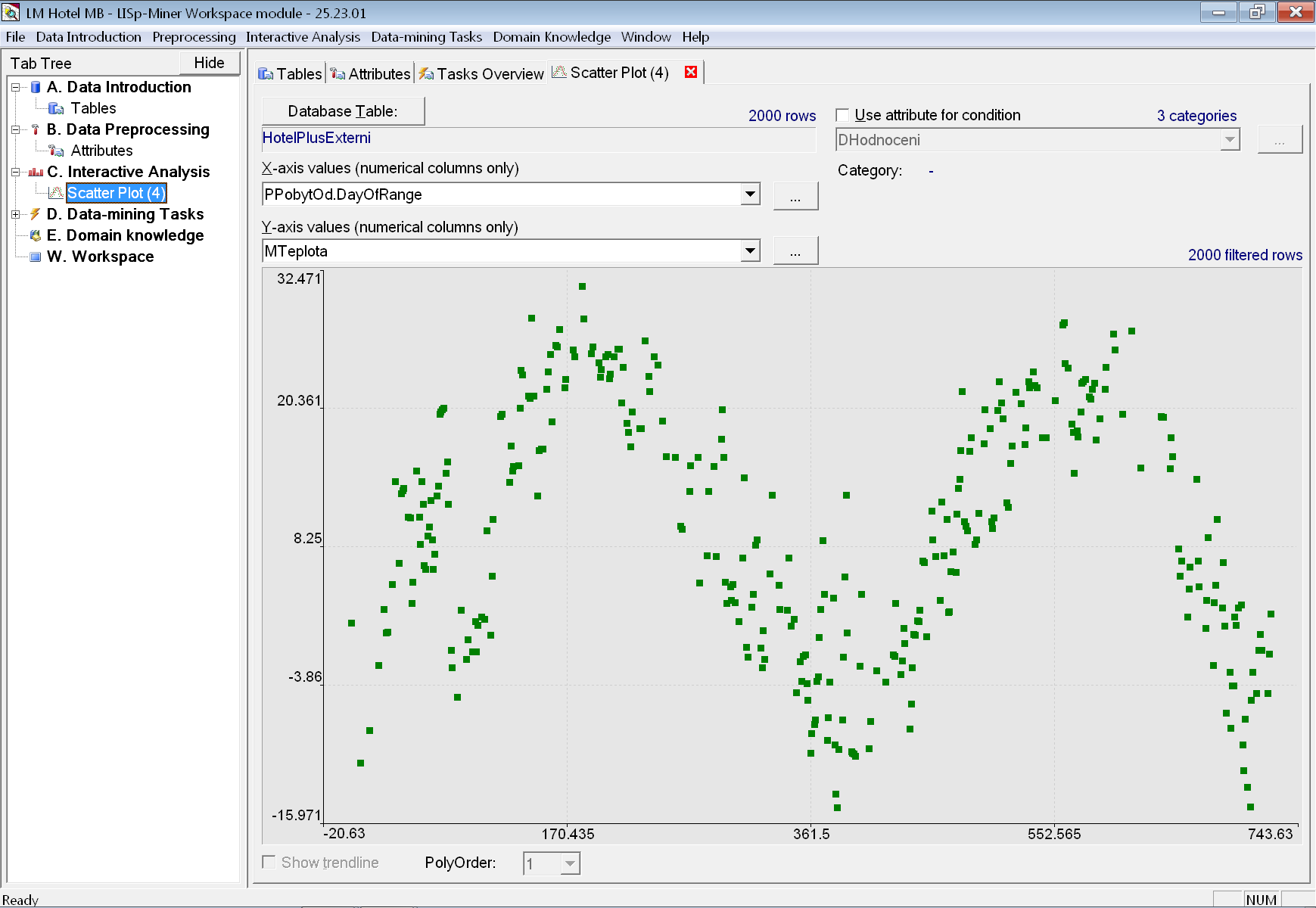
Podobný graf jsme už viděli ve fázi seznámení s propojenými daty. Tehdy jsme však trend viděli pouze proto, že data byla v importovaném souboru seřazena (což jsme zjistili zobrazením hodnot ve sloupci PPobytOd.DayOfRange).
Ve Scatter-plot analýze vidíme vztah obou sledovaných hodnot (PPobytOd.DayOfRange a MTeplota) bez ohledu na pořadí záznamů v databázové tabulce.
Průběh teplot si dále můžeme nechat zobrazit pro různé typy oblohy v atributu MObloha. Vidíme, jak se liší průměrná denní teplota.
Analýzu hlavních komponent můžeme použít pro zjištění závislostí mezi dílčími a celkovým hodnocení. Otázka zní – lze z dílčích hodnocení spolehlivě odhadnout celkové hodnocení?
Na záložce PCA pomocí tlačítka Columns vložíme do analýzy všechny čtyři sloupce dílčího hodnocení. Zároveň si body necháme obarvit podle celkového hodnocení (atribut DHodnoceni).
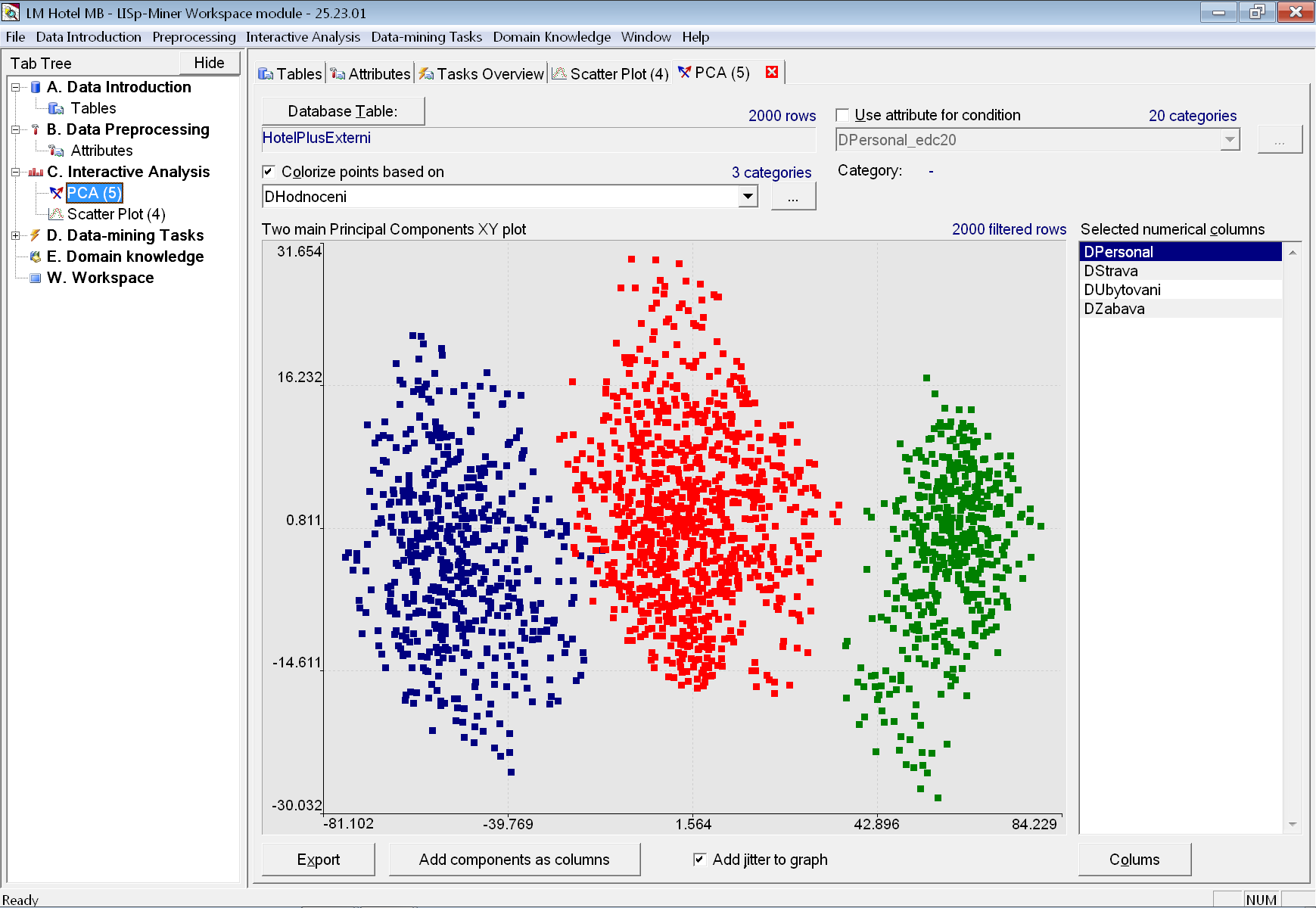
Nyní vidíme, že dílčí hodnocení skutečně s velkou jistotou určují celkové hodnocení. Spokojení hosté (zelený „mrak“ vpravo) jsou jasně odlišitelní, zatímco mezi průměrem a nespokojenými je částečný překryv.
I zde můžeme zkoušet, jak se shluky mění pro různé podmnožiny – např. pro hosty bez stravy, pro hosty mimo sezónu atp. K dispozici pro definici podmnožiny máme všechny atributy vytvořené ve fázi předzpracování. Protože je atributů hodně a ještě více je jejich kombinací, bývá pro nalezení nejlepší vhodné použít analytickou proceduru MCluster-Miner.
Přesuneme se od analýzy hodnot ve sloupcích k interaktivní analýze kategorií atributů.
V souvislosti s právě provedenou analýzou hlavních komponent budeme chtít vypočítat korelační koeficienty mezi atributy ve skupině Hodnocení, tedy korelační koeficienty mezi celkovým a dílčími hodnoceními.
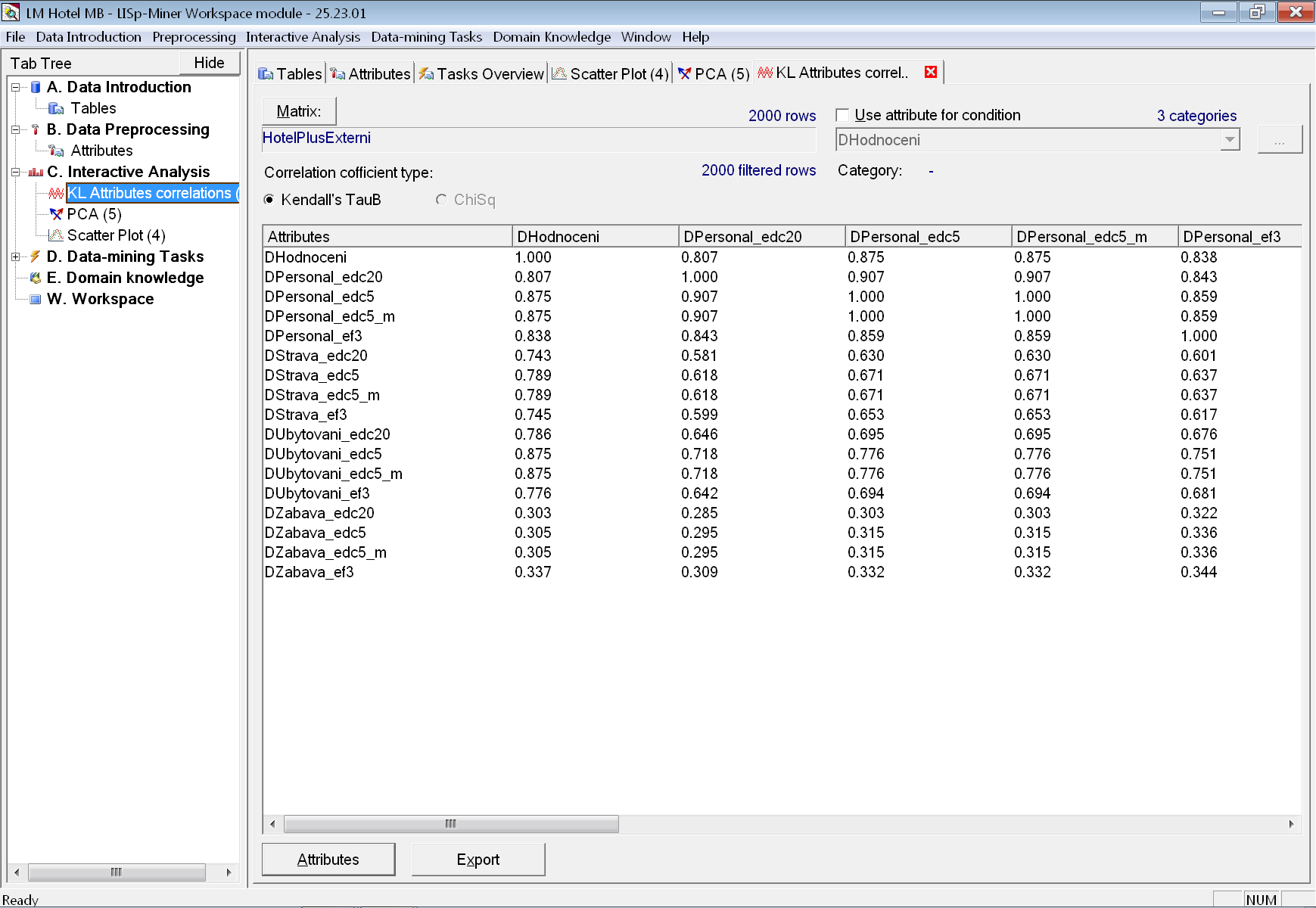
Vidíme, že bude nejlépe s celkovým hodnocením koreluje dílčí hodnocení personálu spolu s dílčím hodnocením ubytování. Naopak dílčí hodnocení možností vyžití v okolí až takovou korelaci nevykazuje.
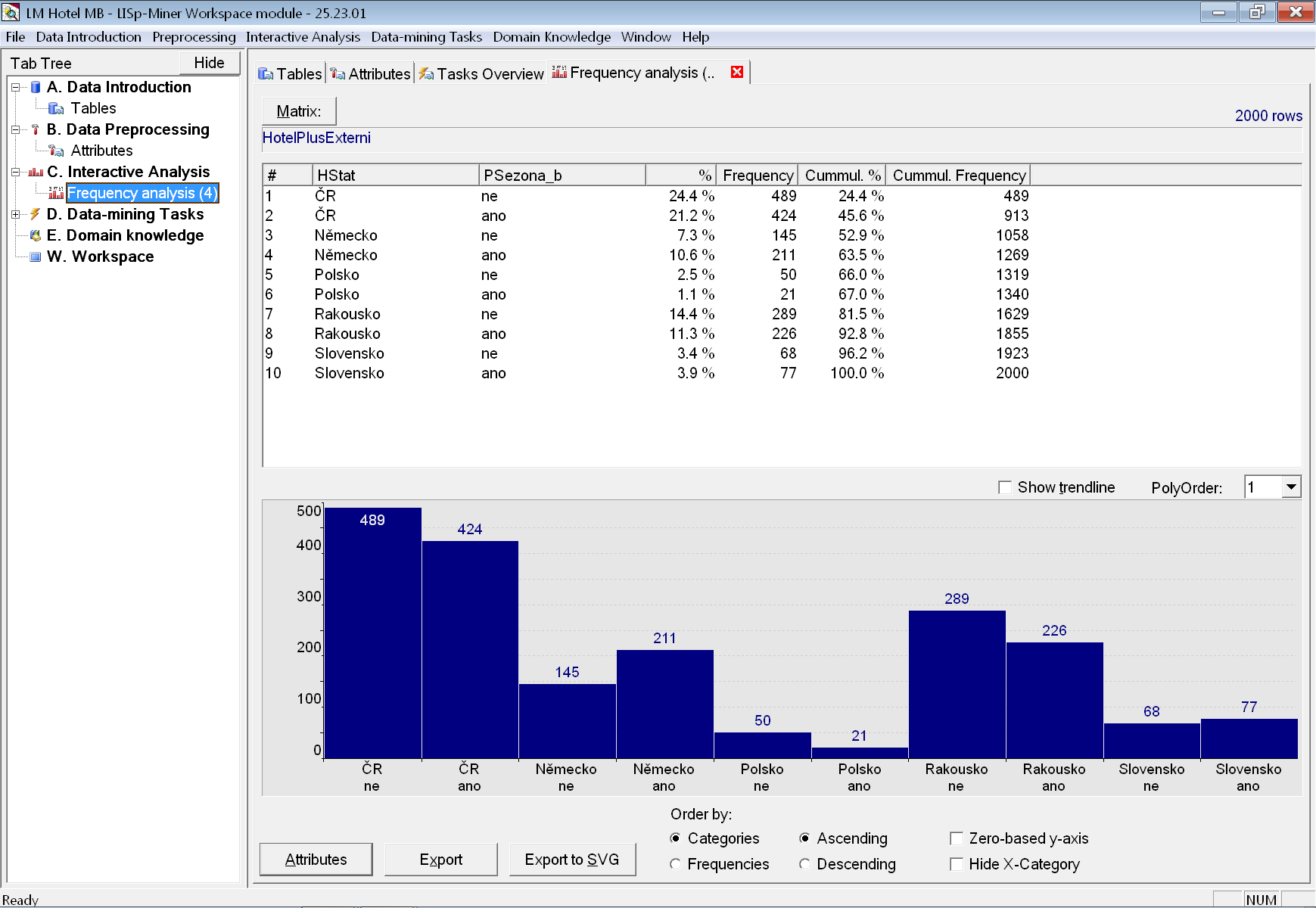
Nyní zaměříme svoji pozornost na atributy ze skupiny Host. Nejprve si zobrazíme frekvenční analýzu kategorií atributu (resp. atributů). Nejprve vybereme pomocí tlačítka Attributes atribut HStat.
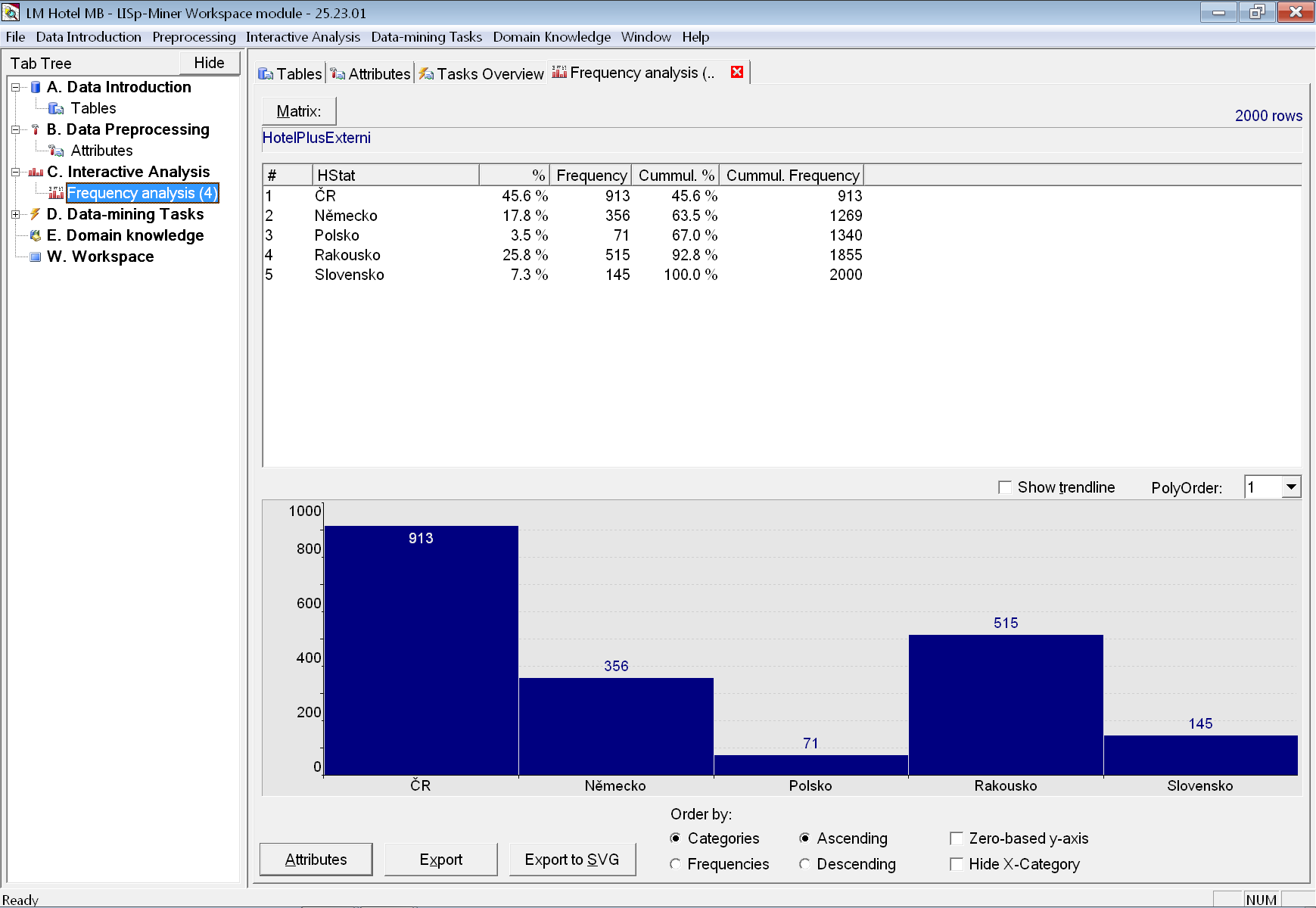
I tento graf jsme už měli možnost vidět při zobrazení detailních informací o sloupci HStat. Je však důležité mít na paměti, že tentokrát se díváme na frekvence kategorií atributů, které mohou sdružovat více hodnot původního databázového sloupce, nebo naopak některé ignorovat (i když v tomto případě tomu tak není).
Navíc však můžeme přidat ještě dichotomický atribut PSezona_b a zkoumat kombinace četnosti hostů podle státu a toho, zda přijeli v sezóně, či mimo ni.
Zajímá-li nás rozdělení frekvencí kategorií pouze jednoho atributu, může být přehlednější zobrazení záložky s CF analýzou. Stejně jako ostatní interaktivní analýzy ji můžeme otevřít z menu Interactive Analysis, ale obvykle bude pohodlnější použít tlačítko Show CF přímo na záložce atributu.
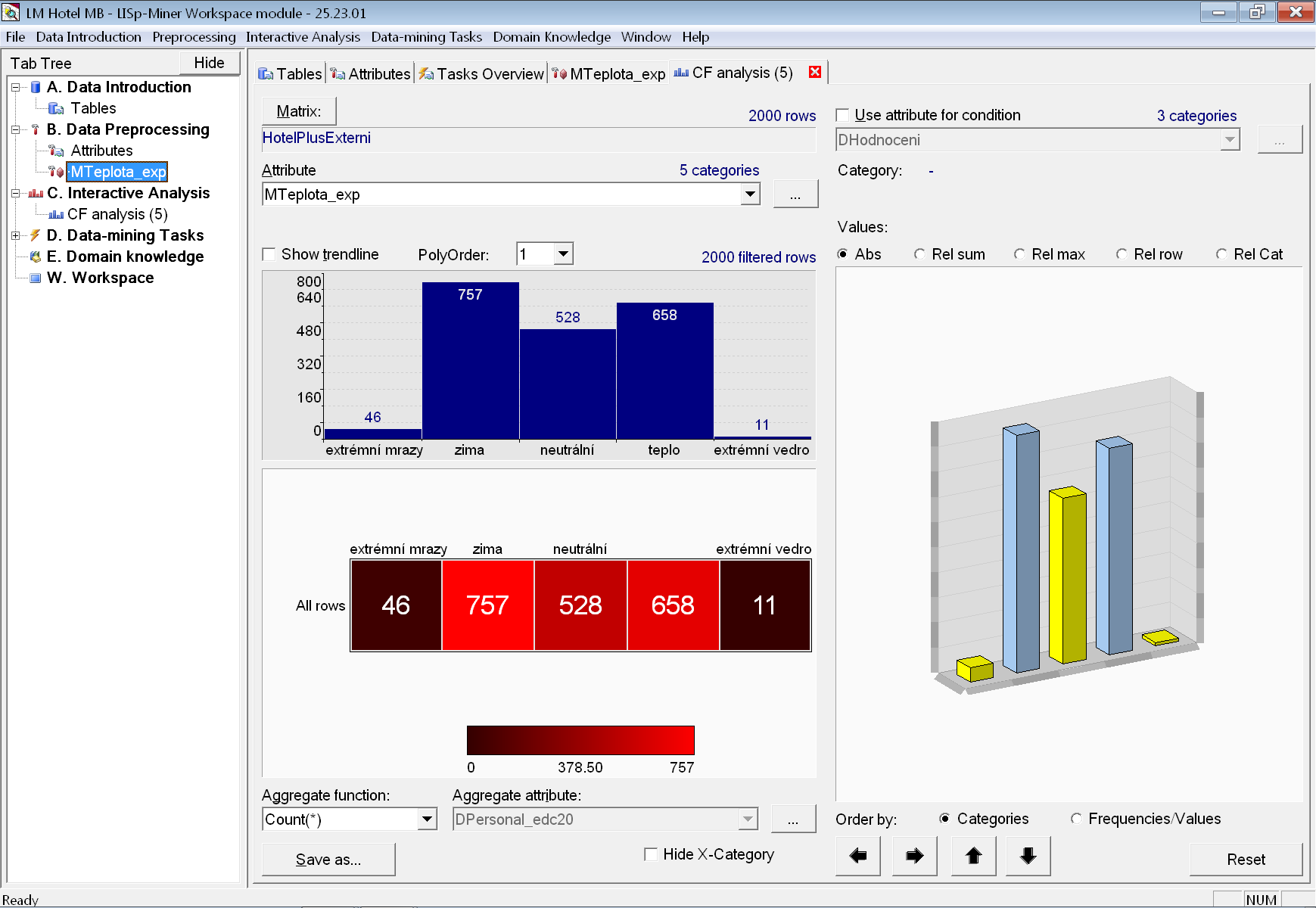
Zobrazíme se například CF analýzu pro atribut MTeplota_exp s expertním rozdělením teplot. Vidíme, že pro období extrémních mrazů máme 46 pobytů, kdežto pro extrémní vedra pouze 11.
Když však omezíme podmnožinu záznamů pouze na spokojené hosty (atribut DHodnoceni = spokojen) vidíme, že ze 46 pobytů za extrémních mrazů byl pouze 9 spokojených hostů. To je možná inspirace pro hlubší analýzu.
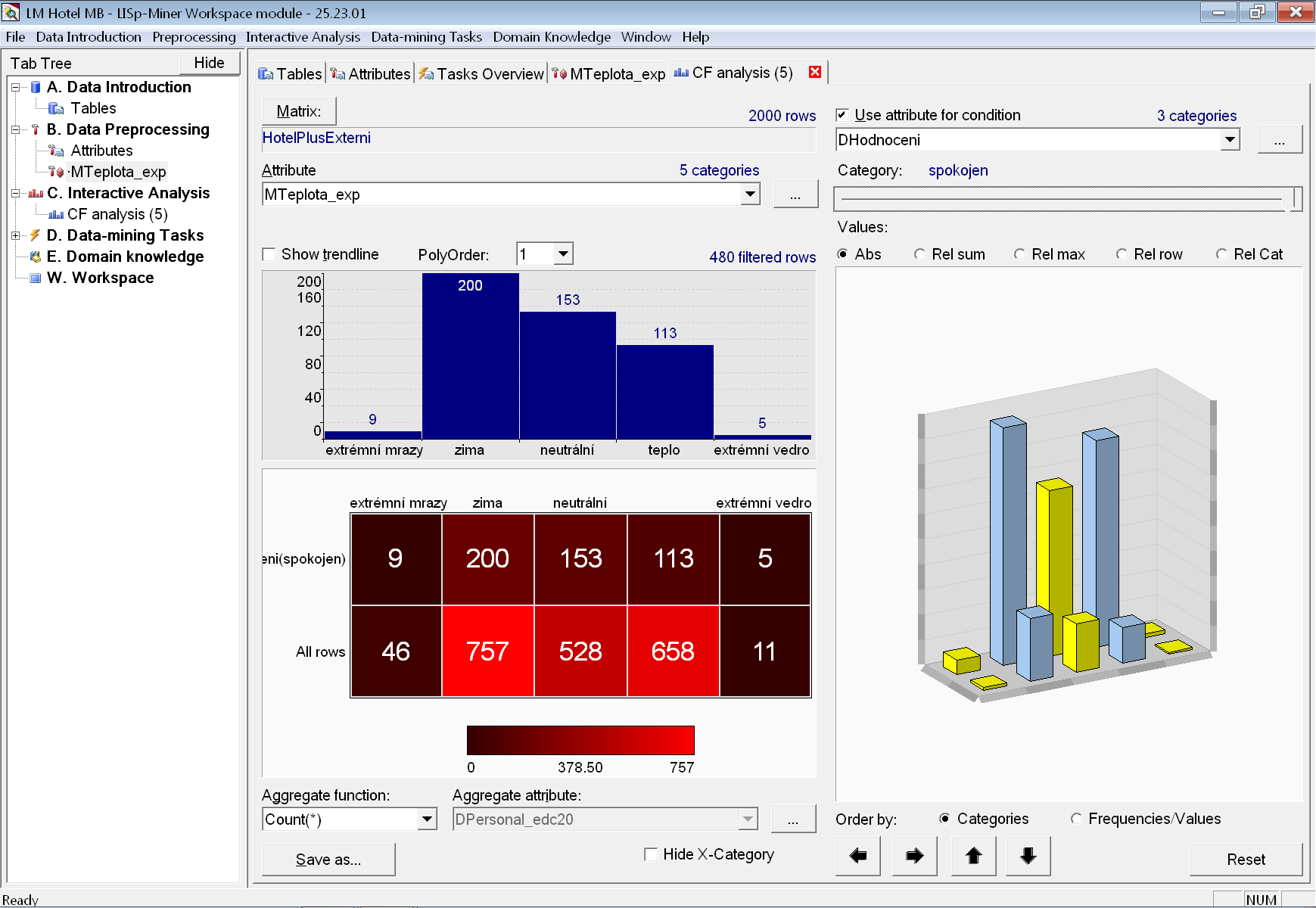
Zároveň však vidíme, že spokojení hosté jsou spíše při nižších teplotách. Pro teplejší dny spokojených hostů ubývá, přestože hostů je přibližně stejně v zimě i v létě (viz obrázek výše).
Četnosti kombinací kategorií dvou atributů zkoumáme pomocí kontingenční KL analýzy. Na záložce vybereme z rozbalovacích nabídek první (řádkový) a druhý (sloupcový) atribut, například POsobonoci_ef5 a PCenaCelkem_ef5.
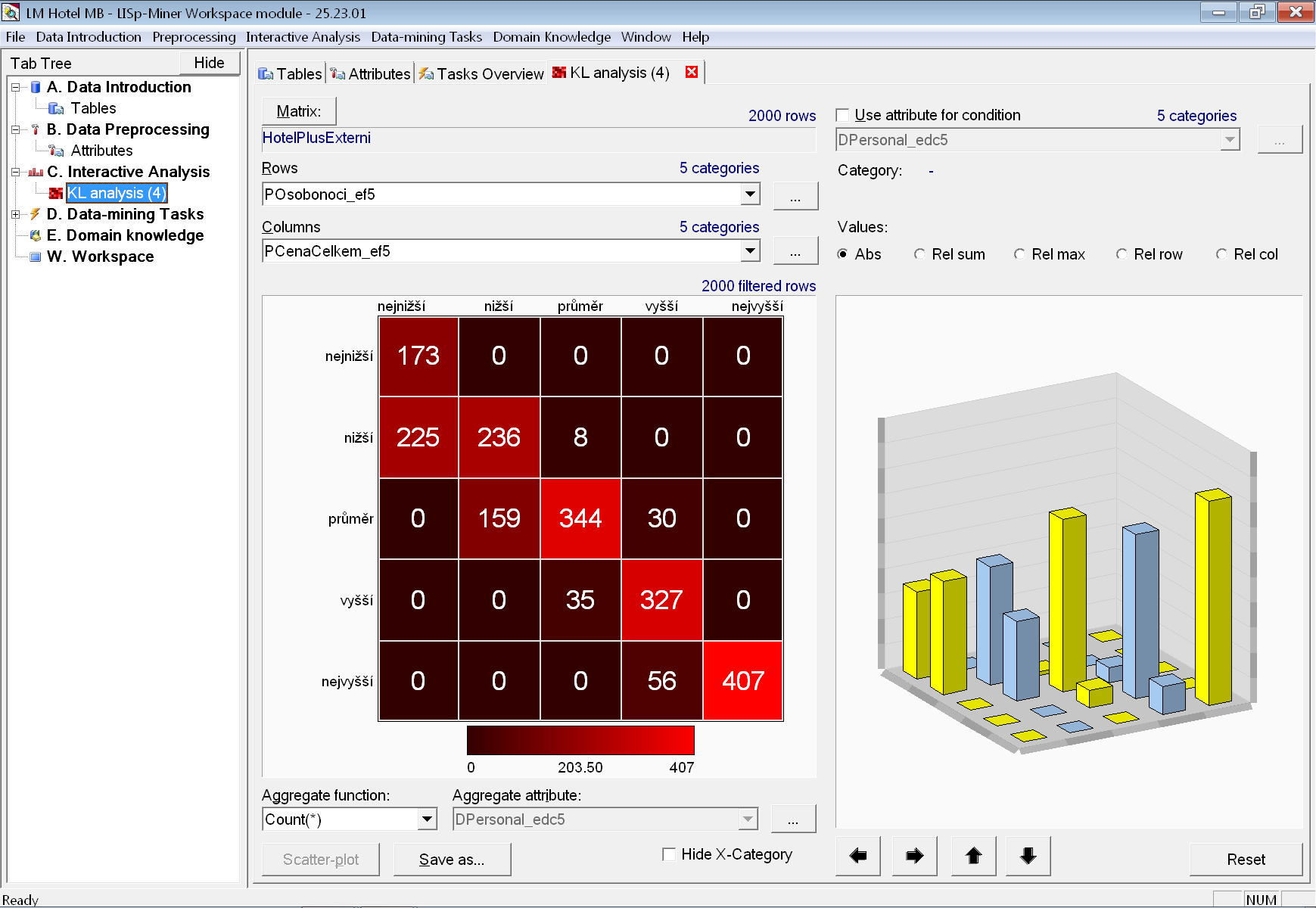
Na obrázku vidíme téměř dokonalou podobu přímé ordinální závislosti mezi počtem osobonocí a celkovou cenou pobytu. Ta se vyznačuje nahromaděním vyšších četností přibližně na hlavní diagonále kontingenční tabulky. Jde o logický důsledek toho, jakým způsobem je cena za ubytování počítána.

Jak jsme si ukázali v analýze hlavních komponent, jsou v dílčích hodnoceních jasně odlišitelné shluky. Přirozená otázka proto je, zda lze vytvořit rozhodovací strom, který s velkou mírou přesnosti dokáže z dílčích hodnocení určit hodnocení celkové.
Otevřeme tedy záložku pro interaktivní vytváření rozhodovacího stromu a jako první krok zkontrolujeme, že je správně zadaná cílová třída DHodnoceni (v datech Hotel tomu tak je rovnou).
Protože strom budeme vytvářet ručně, tak není vhodné použít atributy s mnoha kategoriemi, které by vedly k příliš košatému stromu. Použijeme proto dříve připravené atributy dílčích hodnocení se třemi kategoriemi jako ekvifrekvenční intervaly (přípona _ef3).
Aby nás ostatní atributy při vytváření stromu nemátly, tak pomocí tlačítka Available attributes nejprve všechny atributy přesuneme do levého seznamu, abychom zpět do pravého přesunuli pouze DUbytovani_ef3, DStrava_ef3, DPersonal_ef3 a DZabava_ef3. V seznamu atributů, kterou jsou k dispozici pro vytváření stromu, jsou nyní pouze tyto čtyři atributy a jsou seřazeny podle významnosti (vhodnosti pro použití ve stromu na daném místě).
Jako nejvhodnější se nabízí atribut DPersonal_ef3, který použijeme pro rozvinutí kořene stromu.
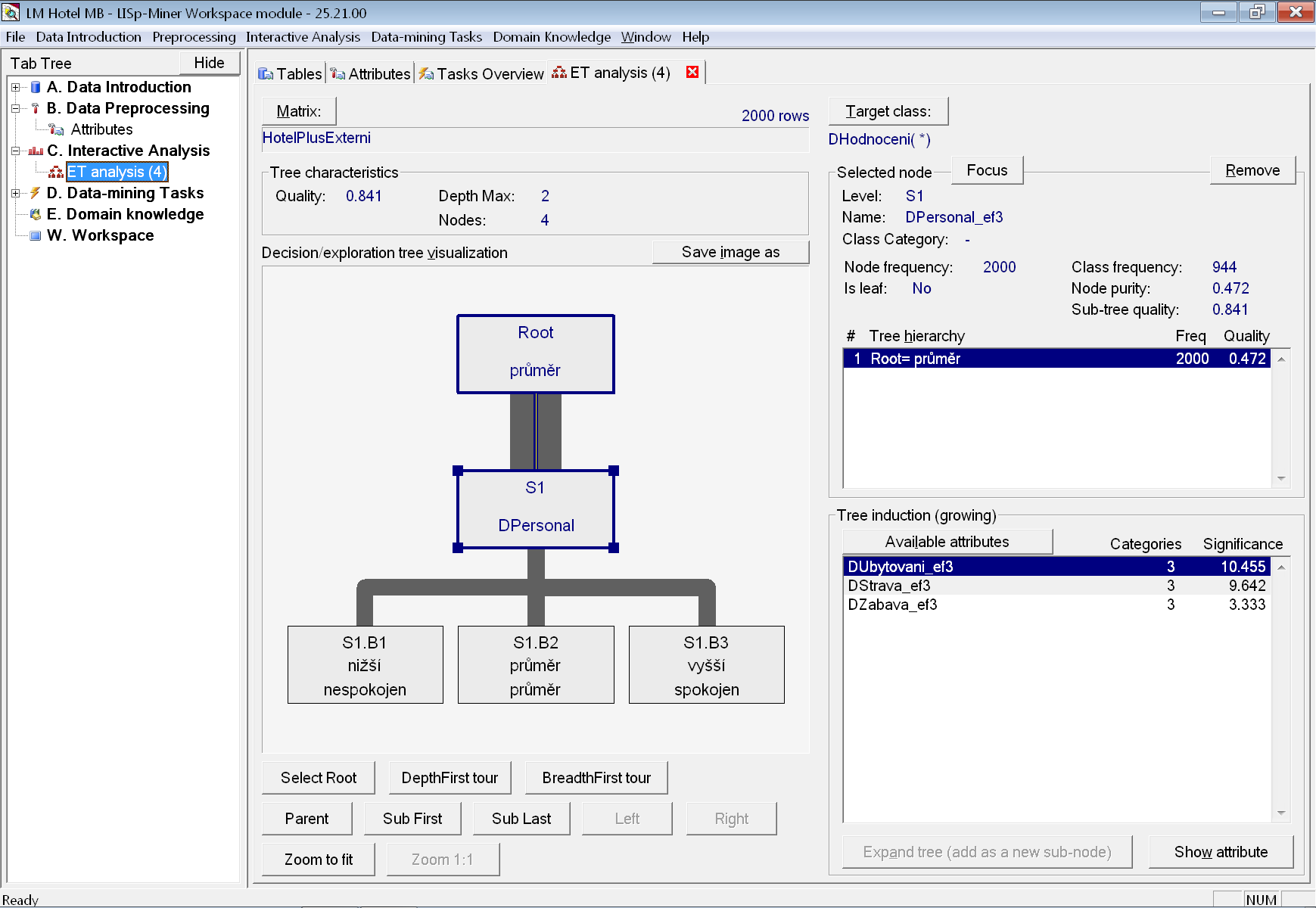
Po přidání atributu vidíme, že už takto jednoduchý strom dosahuje přesnosti ve výši 83,2 %. Zároveň první dva listy (nespokojen a průměr) dosahují čistoty 86,2 % a 95,8 %. Problém je s posledním listem (spokojen), který má čistotu pouze 67,6 %. Použijeme proto další nabízený atribut ze seznamu – DUbytovani_ef3 a uzel rozvineme. Nyní již kvalita stromu stoupla na 91,3 %, jak je vidět na dalším obrázku.
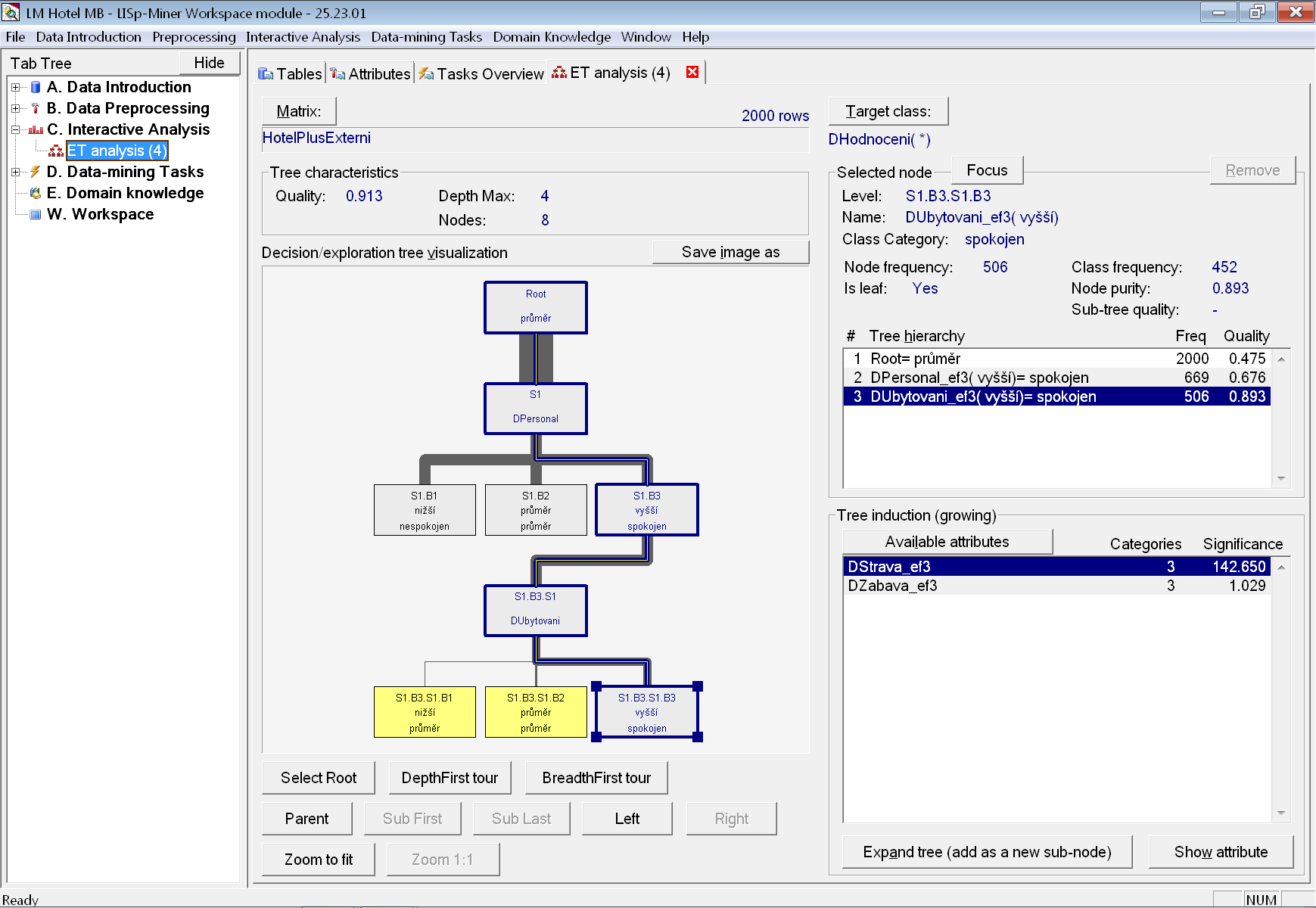
Problematický je opět poslední list (spokojen), u kterého bychom mohli zvážit další rozvinutí. Lepší však bude použít analytickou proceduru ETree-Miner, která pro nás automaticky vytvoří nejlepší strom, případně i s použitím atributů s více kategoriemi.
V analyzovaných datech Hotel jsou přímo geografické souřadnice města, ze kterého host pochází. Dále jsou v datech i názvy států, které nepřímo reprezentují geografické oblasti na mapě. A konečně jsme si i vytvořili odvozené sloupce z geografických dat s názvy HKraj, HNejblizsiHotelVzdalenost a HNejblizsiHotelNazev.
Nejprve se zaměříme na souřadnice měst a použijeme interaktivní analýzu geografických bodů. Protože souřadnice jsou ve sloupcích HMesto_X a HMesto_Y (tedy s názvem končícím na _X a _Y), vyberou se automaticky v rozbalovacích nabídkách X-axis values a Y-axis values. Proto se po otevření záložky zobrazí rovnou města jako body a v případě dostupného připojení na internet se i automaticky stáhne mapový podklad z některé volně dostupné internetové mapové služby.
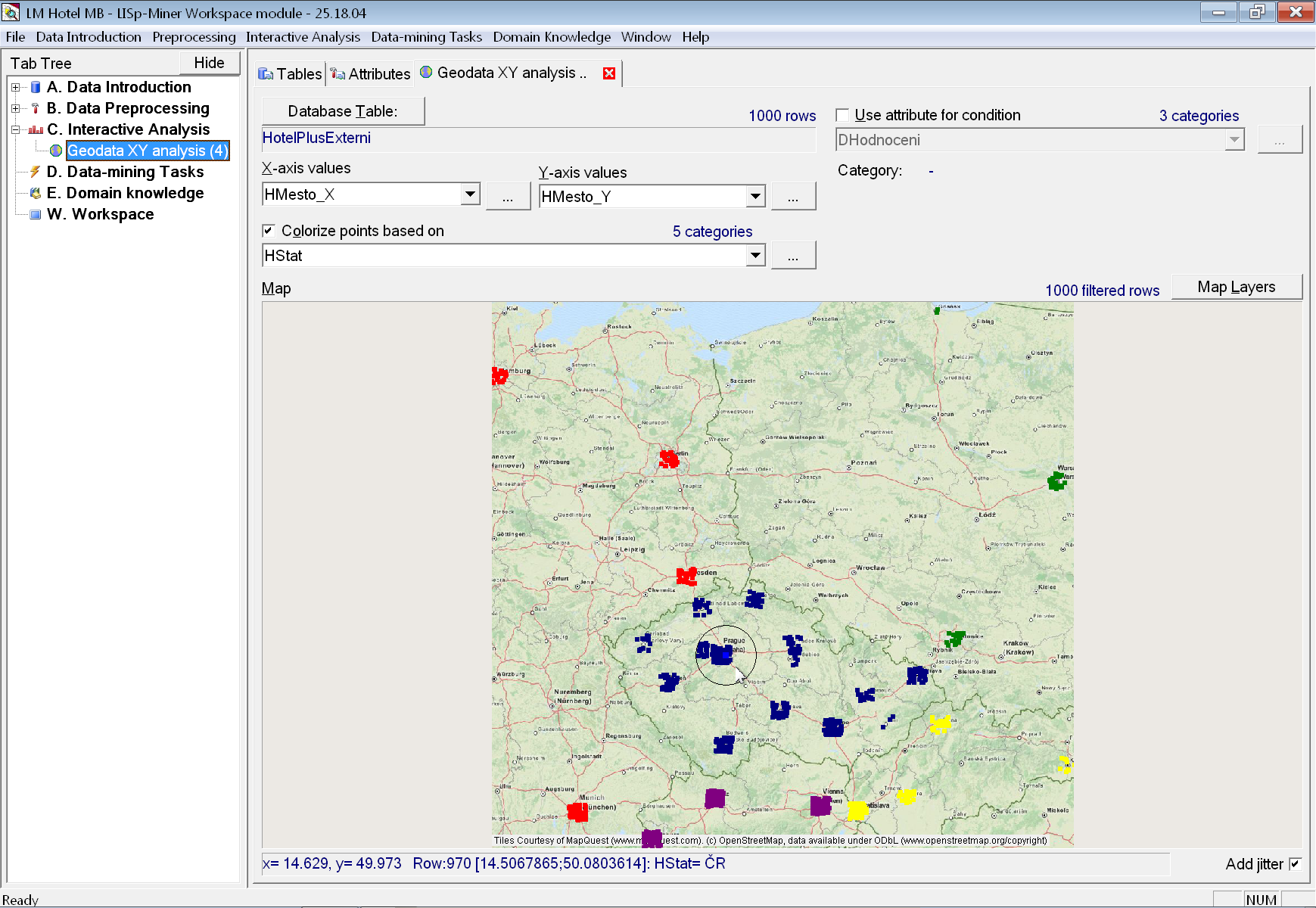
Aby záložka vypadala shodně jako na obrázku, musíme ještě v rozbalovací nabídce Colorize points based on vybrat atribut HStat, aby se body obarvily podle státu, do kterého město patří. A dále musíme zaškrtnout volbu Add jitter, aby byl lépe patrný přibližný počet záznamů z jednoho města (v opačném případě se body pro všechny záznamy z jednoho města překrývají a vidíme pouze jeden bod).
Následně do mapy přidáme vektorovou vrstvu s hranicemi států. K tomu použijeme tlačítko Map Layers. Objeví se dialogové okno pro nastavení mapových vrstev, ve kterém vybereme a z levého do pravého seznamu přesuneme vektorovou vrstvu s hranicemi států střední Evropy (Europe/Central, states).
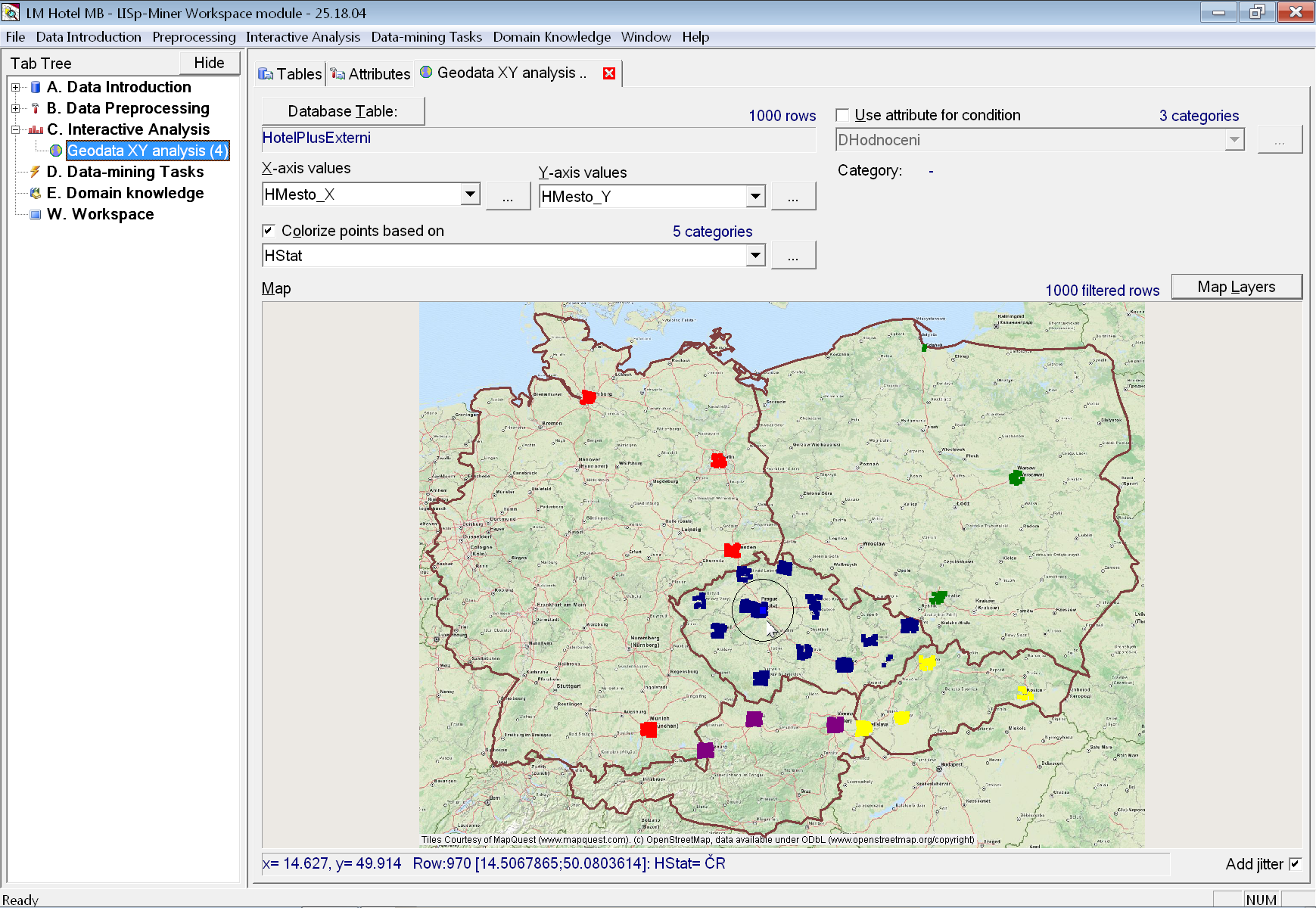
Nyní změníme způsob, kterým jsou body obarveny. V rozbalovací nabídce Colorize points based on vybereme atribut HNejblizsiHotelNazev. Body budou nyní obarveny podle toho, ke kterému z hotelů má host ze svého bydliště nejblíže.
Abychom tomu lépe porozuměli, přidáme do mapy i pozice těchto hotelů. Pomocí tlačítka Map Layers vyvoláme dialogové okno pro nastavení mapových vrstev. Do seznamu vrstev nejprve pomocí tlačítka Add přidáme novou vrstvu Hotel.Konkurence. Data pro ní jsou v souboru Hotel.Konkurence.kml, který jsme již použili při vytváření odvozených sloupců a nalezneme jej ve složce s daty Hotel. Barvu bodů změníme na nějakou výraznou (např. fialovou) a velikost zvýšíme na pět bodů.

Po potvrzení zadání nové vrstvy ji ještě přesuneme do seznamu viditelných vrstev vpravo.

Nyní názorně vidíme jak pozice hotelů, tak pomocí barev i to, ke kterému z nich má každý z hostů ze svého bydliště nejblíže.
Nyní se podíváme na atribut HKraj, který obsahuje jako své kategorie názvy krajů, ze kterých přijeli hosté z České republiky. Kraje představují oblasti na mapě, které mohou být vykresleny různým barevným odstínem podle četnosti záznamů (podobně jako barevná tabulka v CF analýze). Toto umožňuje záložka interaktivní geografická analýza oblastí.
Jako atribut, pro který se interaktivní analýza oblastí má počítat, zvolíme HKraj. Pomocí tlačítka Map Layers pak omezíme mapu pouze na kraje – vrstva Ceska republika, kraje.

Barevné odstíny jednotlivých krajů odpovídají četnosti záznamů, tedy počtu hostů.
Pomocí volby Aggregate function můžeme změnit způsob výpočtu barevného odstínu oblasti. Například je můžeme chtít nastavit podle výše celkových tržeb, a proto zvolíme agregační funkce Sum a atribut PCenaCelkem_edc10. Zároveň nás mohou zajímat pouze spokojení hosté, a proto v nabídce Use attribute for condition vybereme DHodnoceni a posuvníkem nastavíme kategorii spokojen.
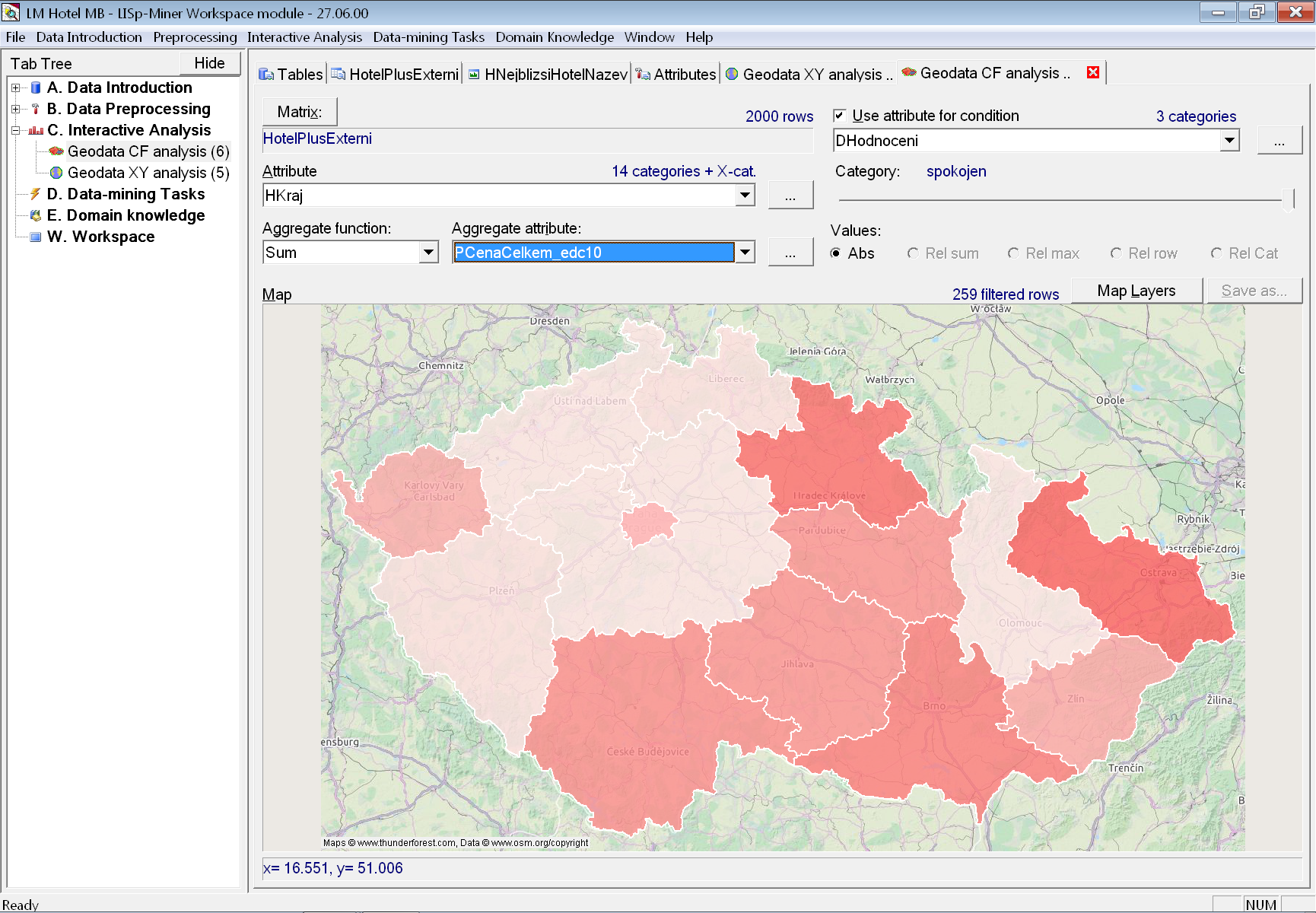
Necháváme na uživateli, aby se zamyslel nad správnou interpretací trochu odlišného rozdělení barevných odstínů jednotlivých krajů.
Upozornění: Toto je pokročilejší funkce, kterou není třeba v základním kurzu 4iz260 procházet.
Atribut HStat obsahuje výčet názvů států, ze kterých hosté přijeli. Státy také představují oblasti na mapě, které můžeme nechat zaobrazit na záložce interaktivní geografická analýza oblastí.
Než však záložku otevřeme, musíme nejprve rozmyslet, kterou vektorovou mapovou vrstvu použijeme pro zobrazení oblastí států. Vzhledem k omezení států pouze na střední Evropu, bude stačit vrstva Europe/Central, states. Důležité však je, jak jsou v definičním souboru této vrstvy pojmenovány jednotlivé oblasti (v tomto případě státy). Musíme totiž zaručit, že názvy kategorií vybraného atributu budou odpovídat těmto názvům.
V základní složce systému LISp-Miner nalezneme podsložku Maps/Vector a v ní soubor Europe.Central Europe.States.kml. Soubory Keyhole Markup Language jsou XML soubory a můžeme je otevřít v libovolném textovém editoru.
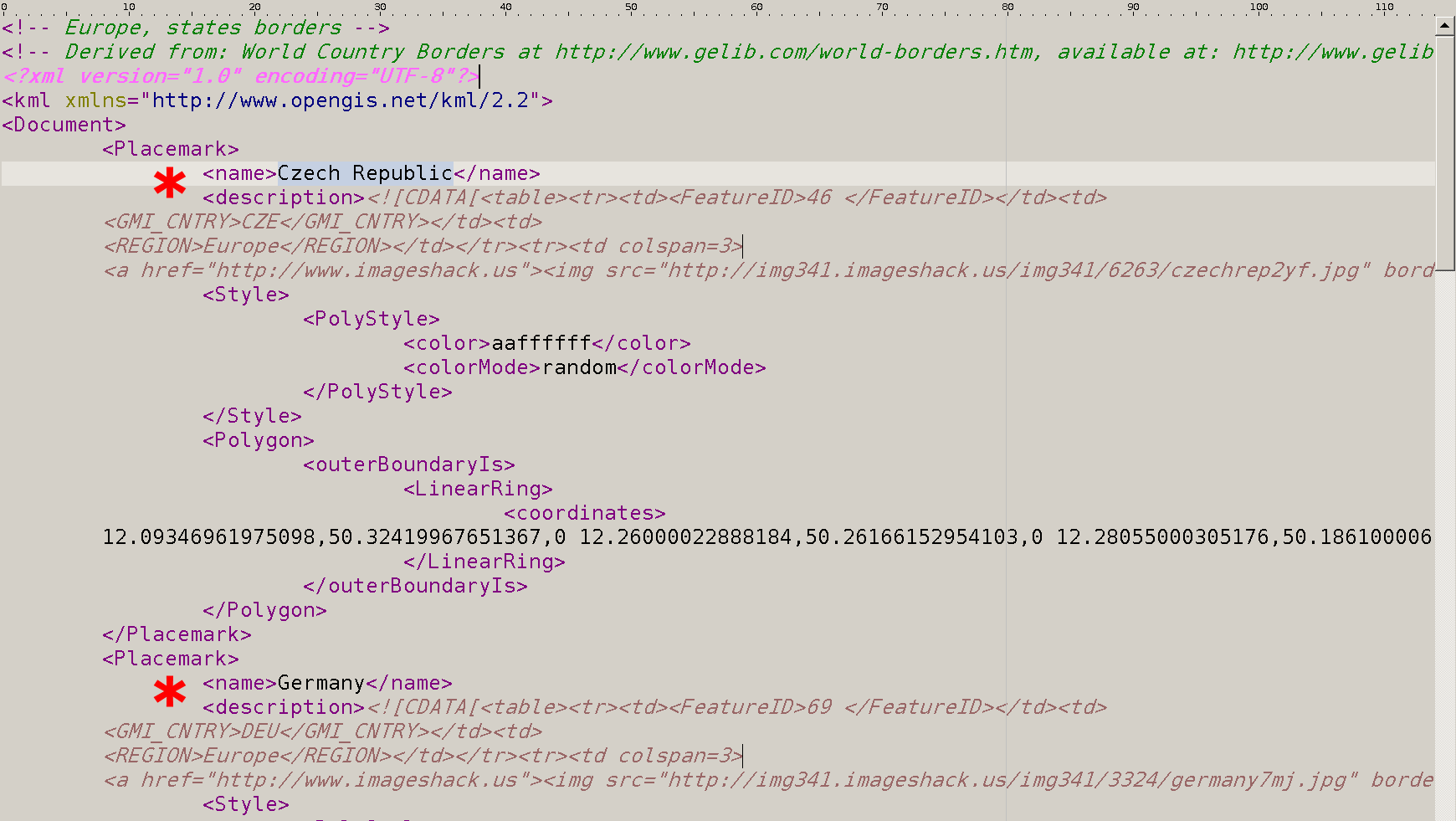
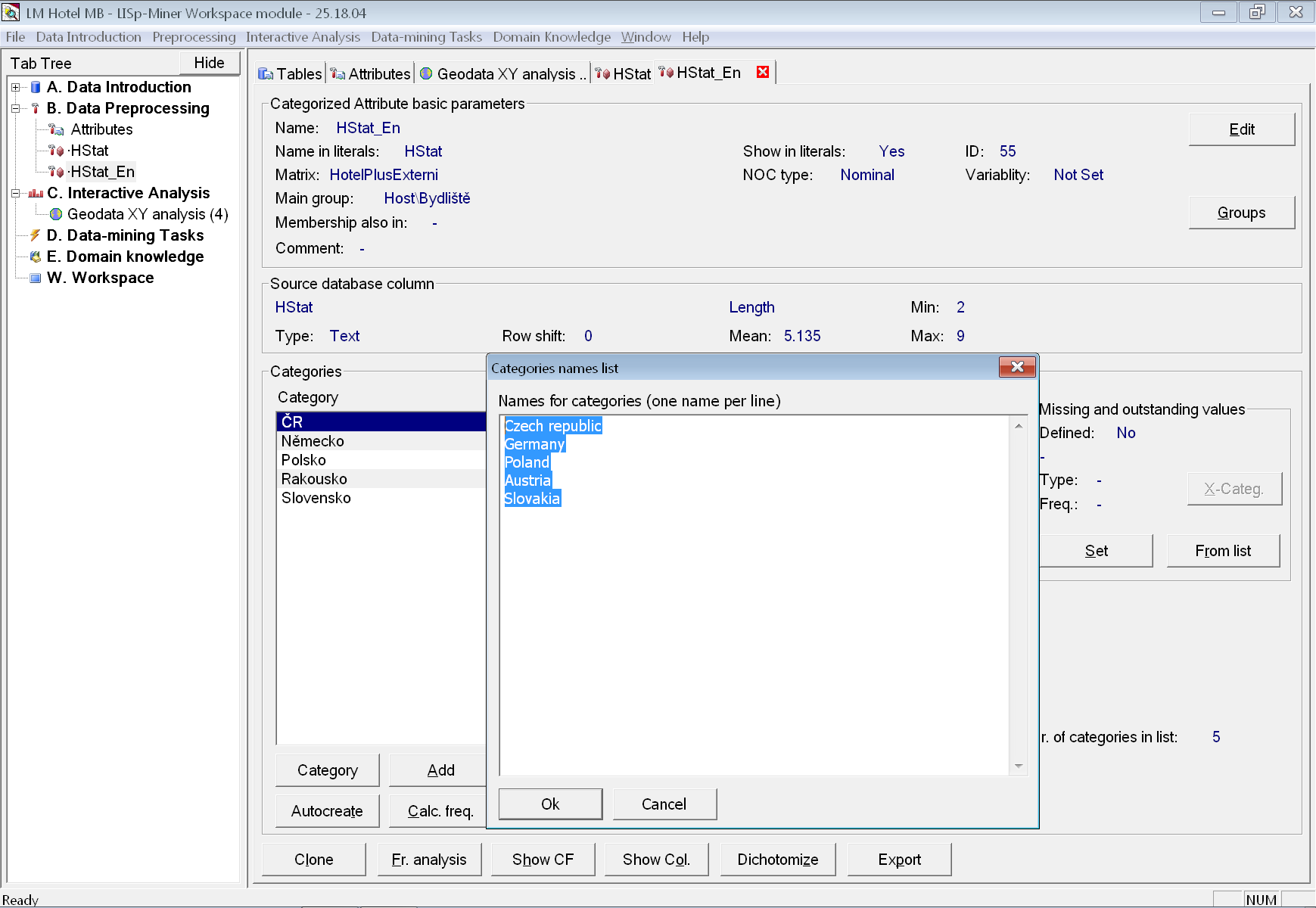
Na obrázku vidíme začátek souboru Europe.Central Europe.States.kml. Hvězdičkami jsou označené tagy <name> definující názvy oblastí. Vidíme, že státy jsou pojmenovány anglicky. Přitom v námi vytvořeném atributu HStat máme pojmenované kategorie česky (jak byly i přímo v datech). Proto vytvoříme klon atributu HStat, který pojmenujeme HStat_En a pomocí funkce pro hromadné přejmenování kategorií nahradíme české názvy za anglické.
Nyní již můžeme otevřít záložku interaktivní geografické analýzy oblastí a nezapomeneme změnit atribut v rozbalovací nabídce Attribute na HStat_En.
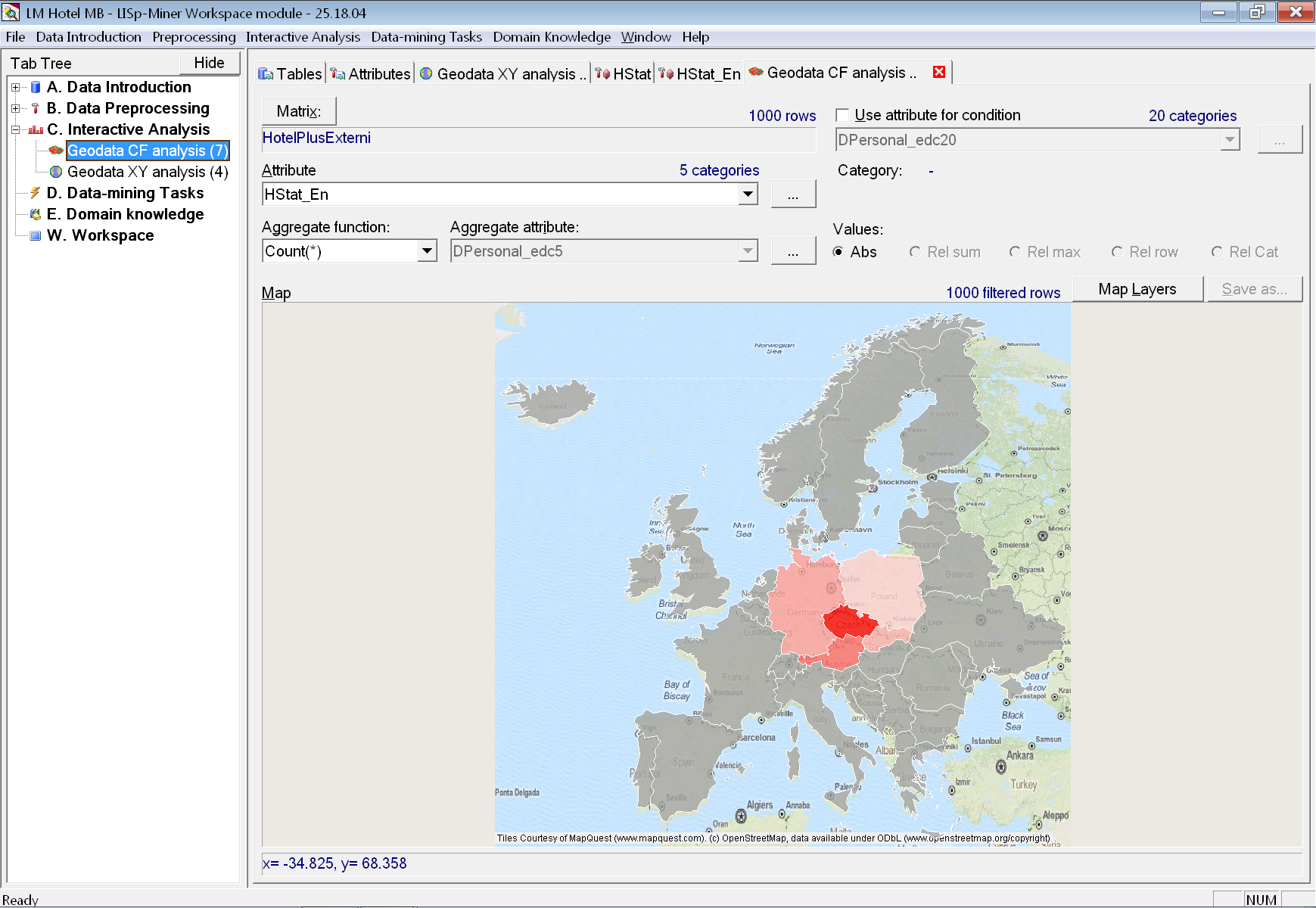
Protože přednastavenou vektorou vrstvou je celá Evropa, opravíme pomocí tlačítka Map Layers pouze na Europe/Central, states.
Související témata:
![]() Demo Hotel: Úvodní přehledový postup analýzy
Demo Hotel: Úvodní přehledový postup analýzy
![]() Interaktivní analýza
Interaktivní analýza
