Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Ve skupině Dotazník nejprve vytvoříme atribut DHodnoceni pro celkové hodnocení pobytu s kategoriemi pro každou z hodnot.
V dialogovém okně pro opravu základních údajů o atributu opravíme typ na ordinální, protože jde o tři stupně hodnocení.
Upozornění: Pokud je atribut správně označen jako ordinální, přitom kontrola obsahu metabáze hlasí, že jde o chybu, je třeba stáhnout aktuální verzi souboru Hotel.MBCV.zip. Alternativně můžeme vrátit typ atributu na nominální.
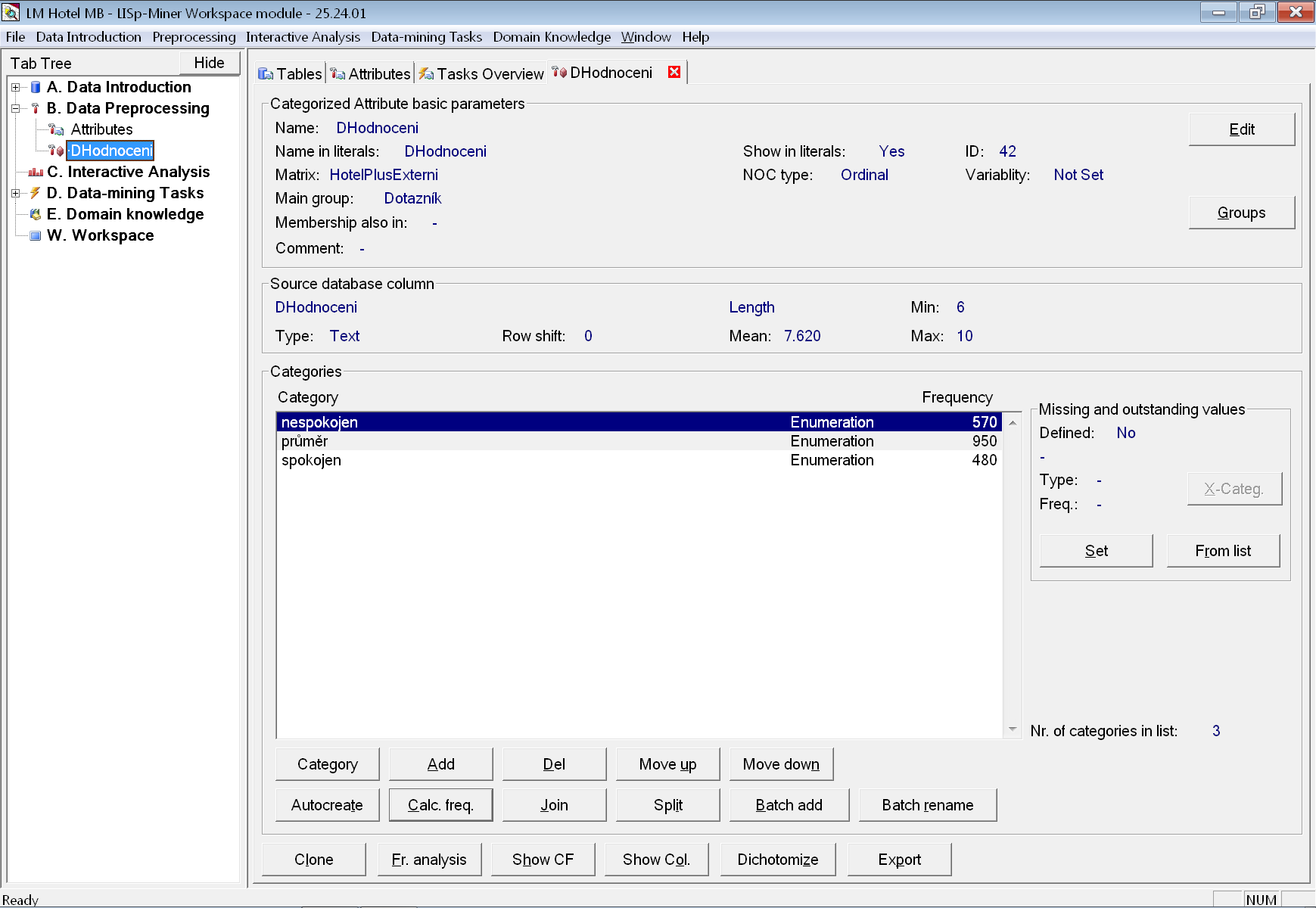
Po vygenerování kategorií zkontrolujeme, že jsou ve správném pořadí. Kategorie se automaticky vygenerují v pořadí podle abecedy. V případě atributu DHodnoceni zároveň odpovídá i stupňům hodnocení (nespokojen, průměr, spokojen), ale většinou bude potřeba pořadí kategorií opravit pomocí tlačítek Move up a Move down.
Následně vytvoříme najednou atributy pro všechna čtyři dílčí hodnocení. Dílčí hodnocení jsou zadávána v procentech od 0 do 100. LISp-Miner požaduje, že nad všemi použitými sloupci vytvoříme kategorizovaný atribut. Abychom mohli podle předzpracovaných atributů shlukovat, musíme diskretizaci provést dostatečně jemně. Jednou z možností by bylo vytvořit kategorii pro každou z hodnot. Ve většině případů však stačí použít ekvidistantní intervaly v počtu mezi 20 až 50.
Zkontrolujeme, že máme vybranou skupinu Dotazník a po stisku tlačítka Add attribute vybereme najednou všechny čtyři sloupce – DPersonal, DStrava, DUbytovani a DZabava. Po stisku tlačítka Create attribute opravíme název pro první atribut na DPersonal_edc20.
V dialogovém okně pro automatické vytváření kategorií zvolíme ekvidistantní intervaly v počtu 20 a zkontrolujeme, že meze jsou od 0 do 100 (hodnocení je v procentech a i když momentálně v datech hodnota 0 není, je dobře s ní počítat například po aktualizaci dat). Následně stiskneme OK.
Nyní se objeví dotaz, zda chceme stejně vytvořit i kategorie pro zbylé označené atributy. Ten potvrdíme tlačítkem Yes. Od teď už budeme jen zadávat názvy pro nově přidávané atributy a jejich kategorie se budou vytvářet automaticky stejně, jako u prvního atributu.
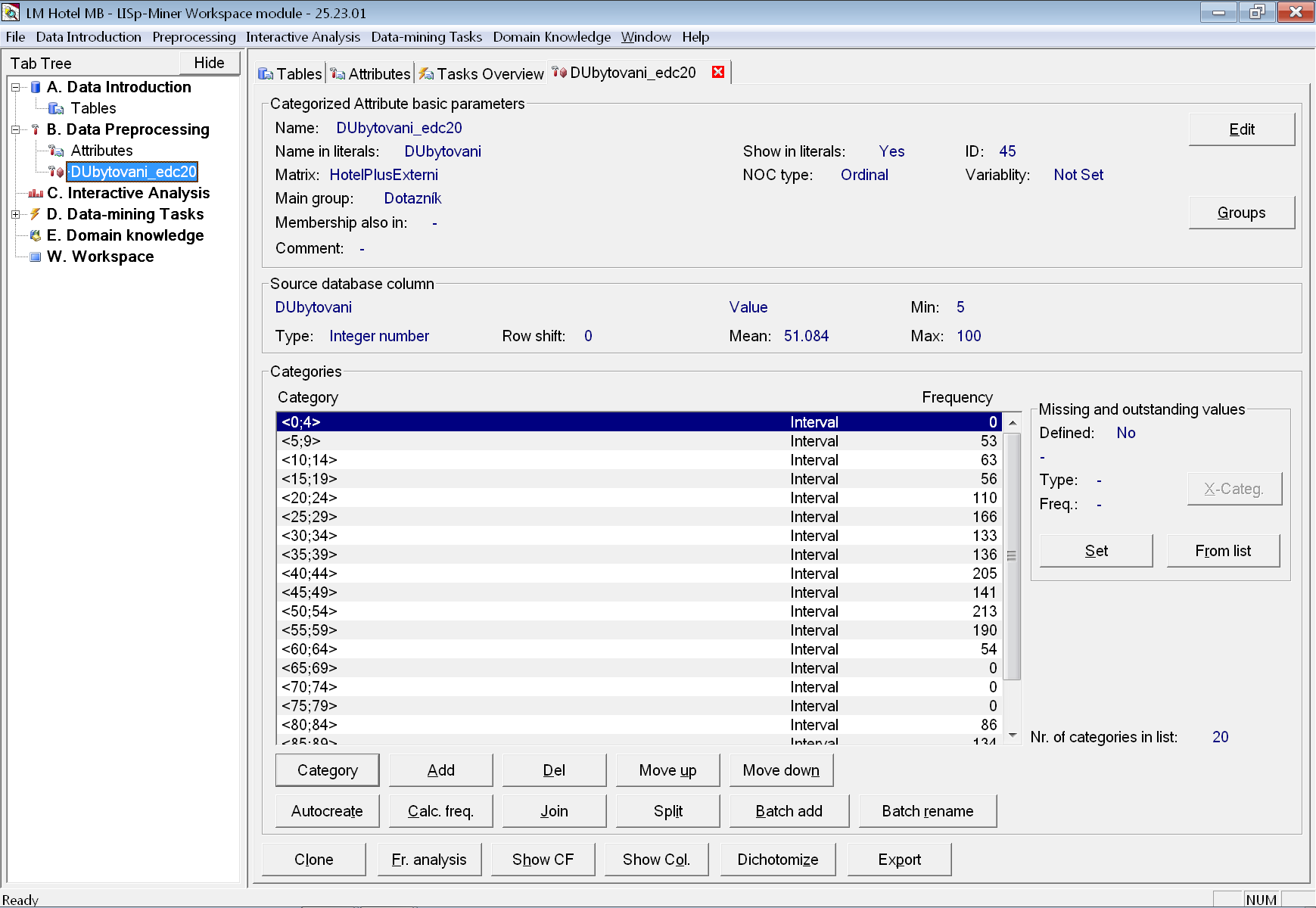
Stejným způsobem přidáme atributy s hrubším členěním hodnocení – na ekvidistantní intervaly v počtu 5. Najednou tak přidáme atributy DPersonal_edc5, DStrava_edc5, DUbytovani_edc5 a DZabava_edc5. Opět nezapomeneme upravit dolní a horní mez na interval 0 až 100.
A konečně ještě vytvoříme nejhrubší členění – pouze na tři intervaly, tentokrát na ekvifrekvenční. Zároveň ponecháme přednastavenou volbu Use mnemonic names.
Najednou tak přidáme atributy DPersonal_ef3, DStrava_ef3, DUbytovani_ef3 a DZabava_ef3.
Na závěr ještě uděláme klon od každého atributu dílčího hodnocení s příponou _edc5 a pojmenujeme jej s příponou _edc5_m. Pomocí tlačítka Batch rename hromadně přejmenujeme kategorie tak, že první interval se bude jmenovat '*' (jedna hvězdička), druhý '**' (dvě hvězdičky) atd. až poslední '*****' (pět hvězdiček).
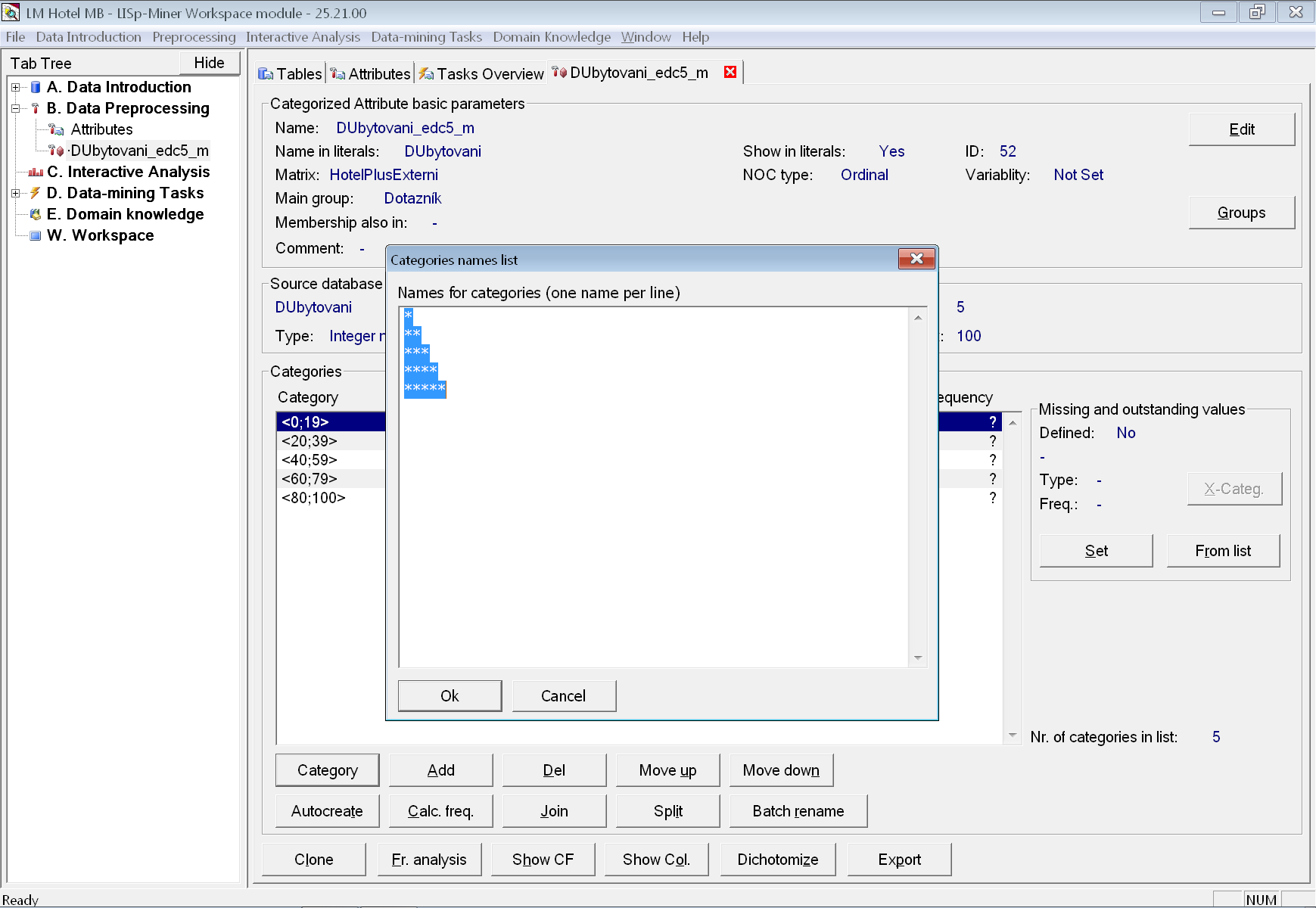
Před stiskem tlačítka OK všech pět názvů označíme a pomocí klávesy Ctrl+C zkopírujeme do schránky systému Windows.
Po vytvoření klonů dalších dílčích hodnocení tak pouze stiskneme Batch rename a místo opětovného zadávání správného počtu hvězdiček pouze vložíme obsah schránky pomocí Ctrl+V.
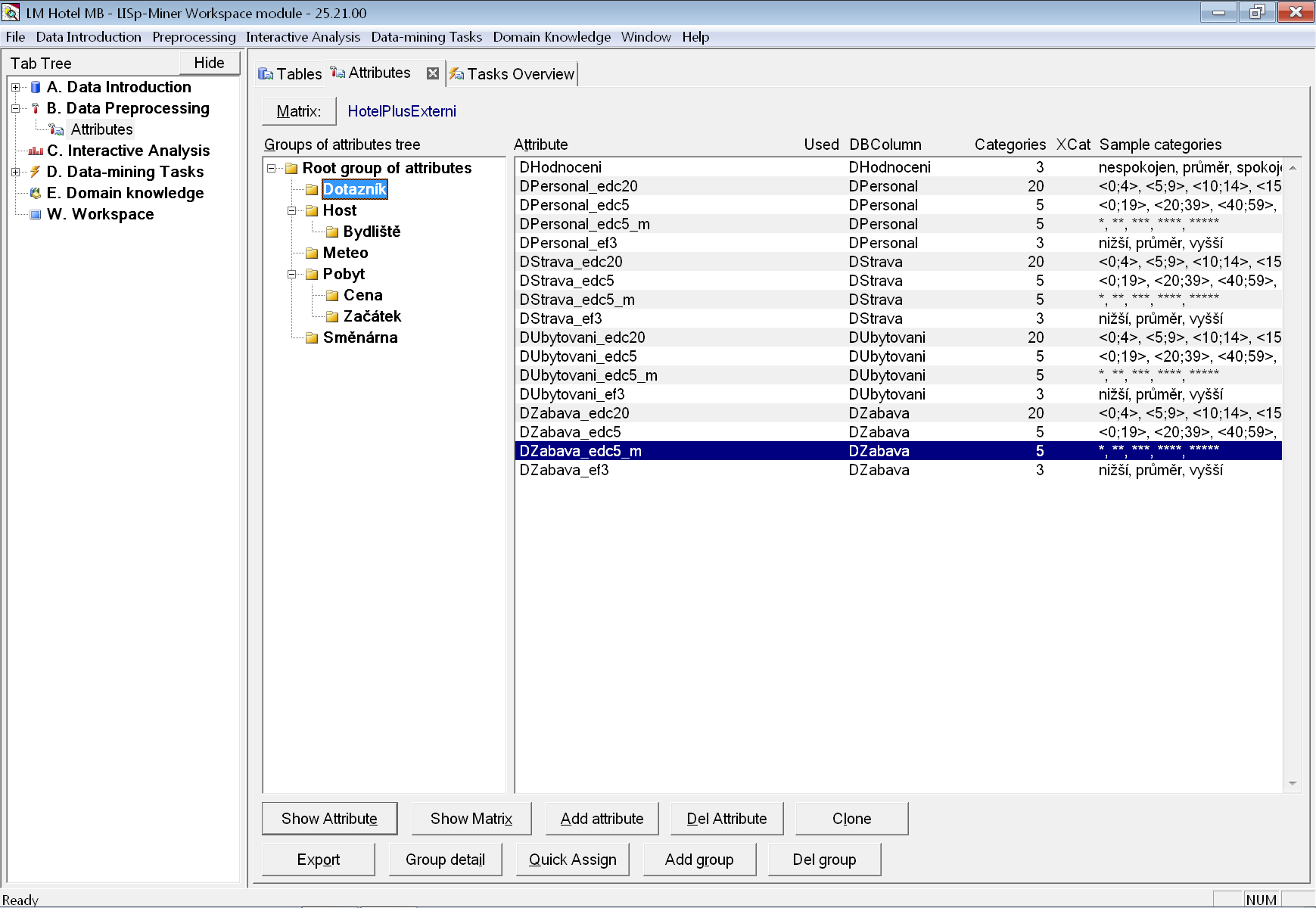
Výslednou podobu skupiny Dotazník vidíme na obrázku.
Související témata:
![]() Demo Hotel: Interaktivní analýza
Demo Hotel: Interaktivní analýza
![]() Demo Hotel: Vytvoření atributů a jejich kategorií
Demo Hotel: Vytvoření atributů a jejich kategorií
![]() Atribut a jeho kategorie
Atribut a jeho kategorie
