Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
![]() Úvodní ukázka je založena na datech Hotel a prochází celý proces DZD od získání a načtení dat, seznámení s nimi a jejich předzpracování až po zadání analytických úloh a interpretaci výsledků.
Úvodní ukázka je založena na datech Hotel a prochází celý proces DZD od získání a načtení dat, seznámení s nimi a jejich předzpracování až po zadání analytických úloh a interpretaci výsledků.
![]() Jak budeme postupovat podle návodu níže, můžeme průběžně kontrolovat, zda jsme vše zadali správně. Na možnost kontroly upozorňuje ikona, kterou vidíme na začátku tohoto odstavce. Na daném místě postupu je vedle ikony i název ověřovací šablony, kterou vybereme v dialogovém okně pro ověření obsahu metabáze vyvolaném pomocí klávesové zkratky
Jak budeme postupovat podle návodu níže, můžeme průběžně kontrolovat, zda jsme vše zadali správně. Na možnost kontroly upozorňuje ikona, kterou vidíme na začátku tohoto odstavce. Na daném místě postupu je vedle ikony i název ověřovací šablony, kterou vybereme v dialogovém okně pro ověření obsahu metabáze vyvolaném pomocí klávesové zkratky Ctrl+F9.
Všechny ověřovací šablony můžeme už nyní stáhnout jako jeden soubor Hotel.MBCV.zip a rozbalit do základní složky systému LISp-Miner. Následně zkontrolujeme, že v základní složce LISp-Mineru máme podsložku ImEx, v ní podsložku MBCV a v ní jednotlivé XML soubory s ověřovacími šablonami.
Získání dat k analýze nemusí byt až tak jednoduché, jak se na první pohled zdá. Vyskytnout se může celá řada technických, ale například i „politických“ důvodů, proč analytik data dostane s časovým zpožděním, v ne zcela vyhovující podobě a něco třeba nedostane vůbec.
Demonstrační data však můžeme jednoduše stáhnout. Pro tuto ukázku zvolíme variantu stažení tří oddělených souborů (Hotel.txt, Meteo.txt a Smenarna.txt). Soubory uložíme do složky Analyza/Hotel, kterou vytvoříme v základní složce systému LISp-Miner nebo kdekoliv na lokálním disku. Zároveň stáhneme a do stejné složky uložíme i mapový soubor Hotel.Konkurence.kml se souřadnicemi konkurenčních hotelů.
Je však třeba si uvědomit, že od zadavatele analýzy obvykle dostaneme pouze obdobu prvního souboru Hotel.txt – data, která má ve své databázi. Je na analytikovi, aby odhadl, která další externí data by mohla přinést zajímavé výsledky. Na této schopnosti do značné míry závisí i přínos celé analýzy.
Ještě před načtením dat do analytického nástroje bychom měli získat alespoň základní představu o jejich struktuře a obsahu. To opět nemusí být tak jednoduché. Pro data Hotel však existuje základní popis. Z něj získáme představu o struktuře dat, významu sloupců a částečně i o hodnotách v nich. Prohlédnout si můžeme i přímo zdrojové textové soubory. Další seznámení s daty můžeme odložit až po jejich načtení do databáze a otevření v systému LISp-Miner.
V praxi může nastat situace, že podrobný popis dat není a analytik si jej musí vytvořit sám. K tomu bude potřebovat konzultace s doménovými a datovými experty, kteří nemusí mít vždy dostatek času a ochoty, aby mu všechny nejasnosti vysvětlili.
Po získání dat k analýze je obvykle musíme načíst do databáze, ze které bude následně čtena nástrojem pro DZD. Zejména u rozsáhlých dat je třeba pečlivě volit, jak a do jakého databázového systému data načteme.
Data Hotel se skládají ze tří textových souborů (Hotel.txt, Meteo.txt a Smenarna.txt) ve formátu CSV. Ty chceme načíst do databáze (v tomto případě postačí MS Access). Použít můžeme buď MS Access, nebo funkci systému LISp-Miner.
![]() Praktická ukázka: Načtení dat Hotel
Praktická ukázka: Načtení dat Hotel
![]() MBCV: Demo Hotel 01 Data Introduction 01 ImportTxt (Hotel.MBCV.zip)
MBCV: Demo Hotel 01 Data Introduction 01 ImportTxt (Hotel.MBCV.zip)
Nyní je možné i první seznámení s daty v právě naimportovaných tabulkách. Můžeme procházet jednotlivé databázové tabulky a zjišťovat základní charakteristiky jednotlivých sloupců. Zobrazit si můžeme i přímo hodnoty v tabulce.
Před další prací zkontrolujeme, že tabulka Hotel má 2000 řádků a tabulky Meteo a Směnárna shodně 731 řádků. Dále si postupně zobrazíme hodnoty v jednotlivých tabulkách a zkontrolujeme, že:
Pokud něco z výše uvedeného neplatí, nebyl proveden správně import dat a je nutné jej provést znovu.
Další seznamování s daty však můžeme odložit až po propojení všech tří tabulek do jedné.
Pro použití většiny metod pro DZD je nutné mít celá data pouze v jedné databázové tabulce. V databázovém prostředí se toto obvykle řeší vytvořením databázového pohledu. Pro usnadnění práce byla funkce propojení dat z více tabulek implementována i přímo v systému LISp-Miner. Nový databázový pohled spojující data z tabulek Hotel, Meteo a Smenarna však můžeme vytvořit i v databázovém prostředí, do které jsme je právě naimportovali – v tomto případě v aplikaci MS Access.
Před vlastním propojováním je nutné pochopit vztahy mezi tabulkami a použité vazební atributy. V našem případě jde o vztah typu hvězda s tabulkou Hotel uprostřed a oběma tabulkami s externími daty po stranách. Vazebním atributem je v tabulce Hotel vždy PPobytOd, v tabulce Meteo pak atribut MDatum a v tabulce Smenarna atribut SDatum.
Při propojování dat z více tabulek nejprve definujeme vztahy (relace) mezi tabulkami. Následně pomocí těchto relací vytvoříme databázový pohled.
![]() Praktická ukázka: Propojení tabulek Hotel, Meteo a Smenarna
Praktická ukázka: Propojení tabulek Hotel, Meteo a Smenarna
![]() MBCV: Demo Hotel 01 Data Introduction 02 HotelPlusExterni (Hotel.MBCV.zip)
MBCV: Demo Hotel 01 Data Introduction 02 HotelPlusExterni (Hotel.MBCV.zip)
Nyní je i vhodný čas pro bližší seznámení s daty v propojené tabulce (resp. dynamicky generovaném databázovém pohledu) HotelPlusExterni.
Nejprve zkontrolujeme, že i nově přidaný pohled HotelPlusExterni má 2000 řádků.
![]() Praktická ukázka: Seznámení s propojenými daty
Praktická ukázka: Seznámení s propojenými daty
V datech lze spočítat celou řadu odvozených hodnot. Některé vycházejí z předaných doménových znalostí, jiné si můžeme domyslet sami. Odvozené hodnoty pomáhají získat trochu jiný pohled na data a zvyšují pravděpodobnost, že v nich najdeme něco skutečně zajímavého.
Před zobrazením podrobného postupu zadání odvozených hodnot se zkuste sami zamyslet, co za hodnoty by z dostupných dat šlo vypočítat.
![]() Praktická ukázka: Zadání výpočtu odvozených hodnot
Praktická ukázka: Zadání výpočtu odvozených hodnot
![]() MBCV: Demo Hotel 02 Data Prepro 01 Odvozené hodnoty (Hotel.MBCV.zip)
MBCV: Demo Hotel 02 Data Prepro 01 Odvozené hodnoty (Hotel.MBCV.zip)
Atribut a jeho kategorie představují transformaci dat vhodnou pro cíle analýzy a použité techniky DZD. V systému LISp-Miner je třeba vytvořit atribut nad každým databázovým sloupcem, který chceme v analýze použít. Obvykle bude navíc vhodné nad jedním sloupcem vytvořit atributů více, každý s jiným způsobem kategorizace.
Větší množství atributů je vhodné rozdělit do skupin, obvykle podle jejich věcné příbuznosti. Praktičtější je nejprve vytvořit strom skupin atributů, a teprve potom přidávat atributy do skupiny, do které patří.
![]() Praktická ukázka: Vytvoření skupin atributů
Praktická ukázka: Vytvoření skupin atributů
![]() MBCV: Demo Hotel 02 Data Prepro 02 Skupiny atributů (Hotel.MBCV.zip)
MBCV: Demo Hotel 02 Data Prepro 02 Skupiny atributů (Hotel.MBCV.zip)
![]() Praktická ukázka: Vytvoření atributů a jejich kategorií
Praktická ukázka: Vytvoření atributů a jejich kategorií
![]() MBCV: Demo Hotel 02 Data Prepro 03 Atributy a kategorie (Hotel.MBCV.zip)
MBCV: Demo Hotel 02 Data Prepro 03 Atributy a kategorie (Hotel.MBCV.zip)
Pomocí funkcí pro interaktivní analýzu se většinou snažíme poznat, co v datech platí obecně. Následně můžeme formulovat vhodné analytické otázky pro hledání podmnožin, kde platí něco jiného. Nejde o data-mining v pravém slova smyslu, protože při interaktivní analýze nastavujeme různé pohledy a omezení zkoumané množiny ručně.
![]() Praktická ukázka: Interaktivní analýza
Praktická ukázka: Interaktivní analýza
Analytické úlohy automaticky prověřují miliony a miliardy různých kombinací na základě námi připraveného zadání. Podle tvaru analytické otázky volíme vhodný typ analytické procedury.
Následují odkazy na ukázkové formulace analytických otázek a jejich řešení.
![]() 01 Převažující den začátku pobytu podle údajů o hostovi a o počasí (CF-Miner)
01 Převažující den začátku pobytu podle údajů o hostovi a o počasí (CF-Miner)
![]() 02 Závislost mezi věkem hosta a celkovou cenou pobytu (KL-Miner)
02 Závislost mezi věkem hosta a celkovou cenou pobytu (KL-Miner)
![]() 03 Typické pobyty podle bydliště hosta (4ft-Miner)
03 Typické pobyty podle bydliště hosta (4ft-Miner)
![]() 04 Shluková analýza dílčích hodnocení dotazníkového šetření (MCluster-Miner)
04 Shluková analýza dílčích hodnocení dotazníkového šetření (MCluster-Miner)
![]() 05 Klasifikace dílčích hodnocení dotazníkového šetření (ETree-Miner)
05 Klasifikace dílčích hodnocení dotazníkového šetření (ETree-Miner)
![]() MBCV: Demo Hotel 04 DM Tasks 99 Všechny úlohy (Hotel.MBCV.zip)
MBCV: Demo Hotel 04 DM Tasks 99 Všechny úlohy (Hotel.MBCV.zip)
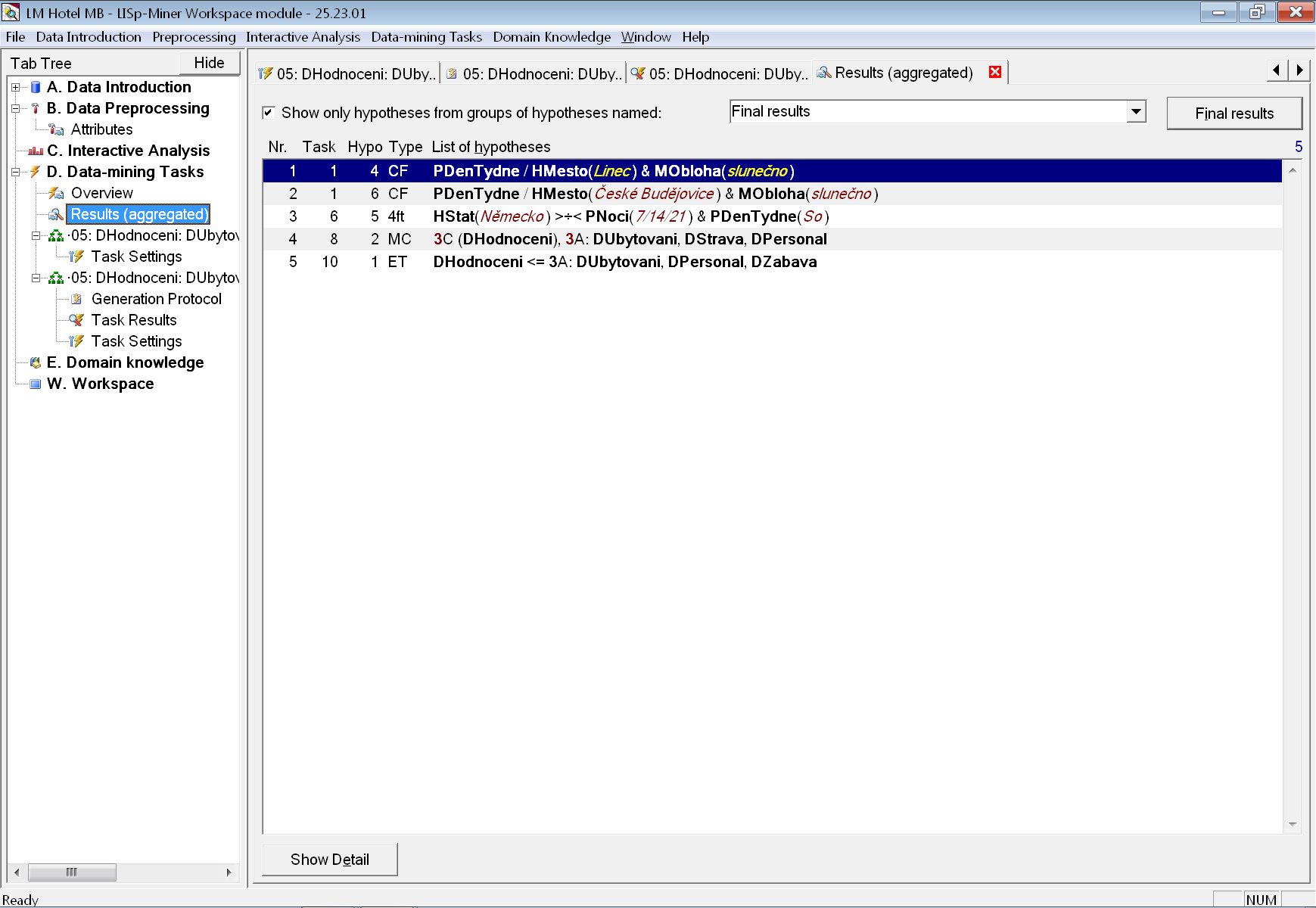
Při tvorbě analytické zprávy můžeme jako vodítko použít seznam nejzajímavějších nalezených vztahů, jak byly postupně vkládány do skupiny Final results: