Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Příklad úlohy pro analytickou proceduru a modul CF-Miner.
Položíme si následující analytickou otázku:
Za „výrazně převažující“ budeme považovat, když daný den v týdnu představuje 50 % nebo více procent všech pobytů v dané podmnožině dat definované podmínkou.
Formálně můžeme otázku zapsat takto:
kde Hotel jsou analyzovaná data, CF určuje použitou GUHA-proceduru, MAX ≥ 50 % C je zápis použitého jednoduchého frekvenčního CF-kvantifikátoru (maximální frekvence má být alespoň 50 % součtu frekvencí v histogramu vypočteného pro aktuální podmínku), PDenTydne je atribut, pro jehož kategorie budou počítány frekvence, a na závěr je uveden seznam skupin atributů použitelných pro generování variant podmnožin dat.
Jako hlavní atribut, pro jehož kategorie se počítají frekvence, by měl být vybírán takový, který má více než dvě kategorie. V opačném případě bývá obvykle lepší použít 4ft-Miner.
V tomto případě použijeme atribut PDenTydne, který má kategorii pro každý den v týdnu, tedy celkem sedm kategorií. To je vhodný počet pro použití v CF-Mineru.
Abychom měli lepší představu o rozložení začátků pobytů podle dne v týdnu na celých datech, provedeme rychlou interaktivní frekvenční analýzu. Tím budeme schopni i lépe posoudit, které z později získaných výsledků analytické procedury jsou zajímavé.
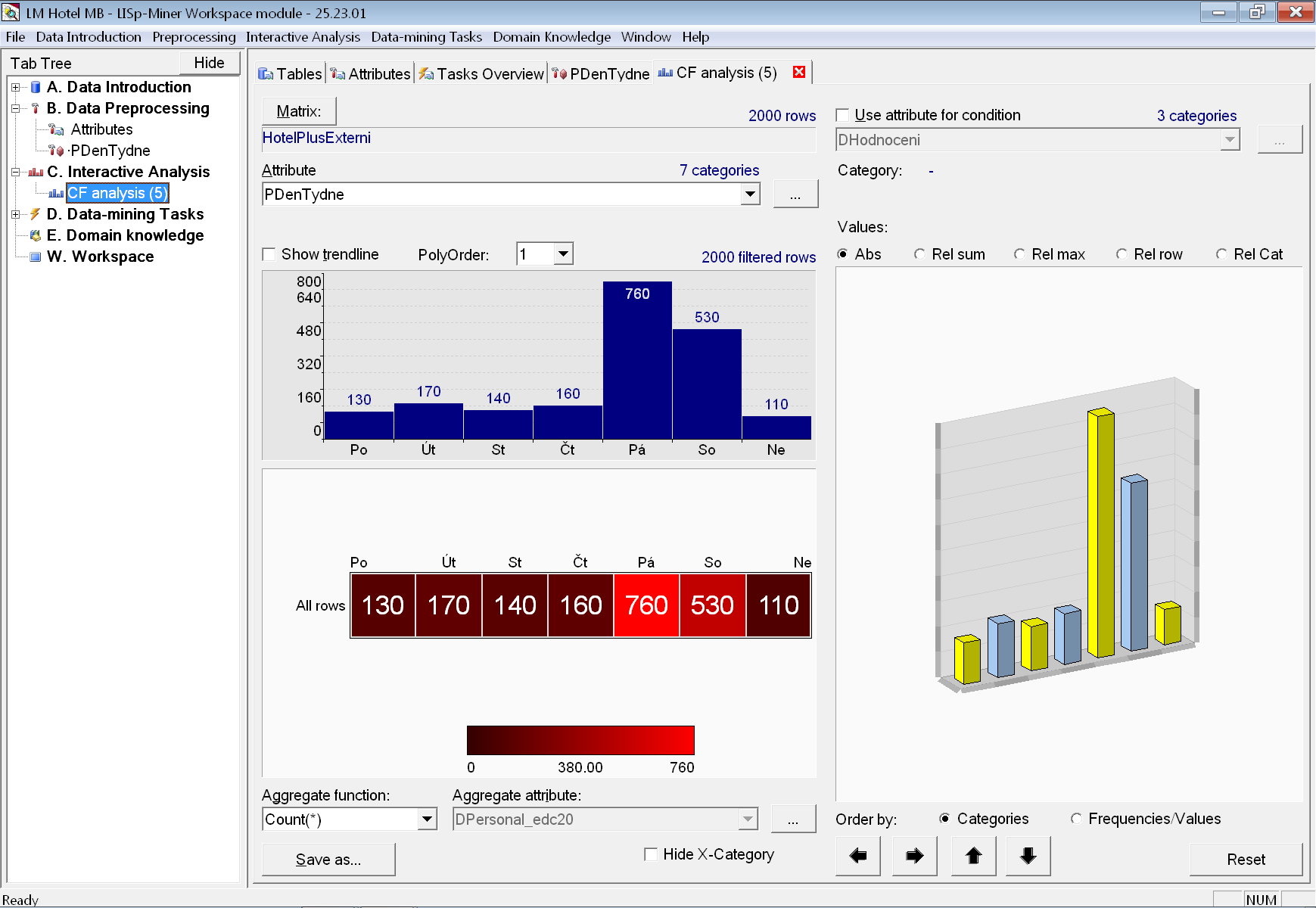
Z grafu je patrná výrazná převaha pobytů začínajících v pátek, s (turnusovými) pobyty začínajícími v sobotu v těsném závěsu. Po přepnutí na relativní podíly (volba Rel Sum) zjistíme, že pobyty začínající v pátek představují 38 % procent, a pobyty začínající v sobotu pak 27 %. Zajímavé by tedy bylo zjistit něco víc o pobytech začínajících v pátek, nebo naopak podmnožinu pobytů, ve které převažuje jiný počáteční den.
Výhodou je, že analytická procedura CF-Miner za nás bude automaticky a systematicky procházet všechny možné takové podmnožiny a testovat, zda v nich převažuje ten, či jiný den začátku pobytu.
Před zadáváním úlohy vytvoříme nejprve novou skupinu úloh, kterou pojmenujeme podle analytické otázky, na kterou bude úloha hledat odpověď – v tomto případě 01: Převažující den začátku pobytu.
Číselný prefix 01 v názvu odkazuje na číslo analytické úlohy a zároveň zajistí řazení skupin v seznamu podle analytických otázek.
Nyní již přidáme novou úlohu pro analytickou proceduru CF-Miner a nazveme ji 01: PDenTydne / Bydliště, Meteo, aby z jejího názvu bylo jednak opět patrné, že odpovídá na první analytickou otázku, ale i to, jaký je použit atribut pro výpočet histogramu a dále skupiny atributů pro generování variant podmnožin dat.
V základních parametrech úlohy po zadání názvu ještě změníme příslušnost úlohy do skupiny, kterou jsme přidali před chvílí.
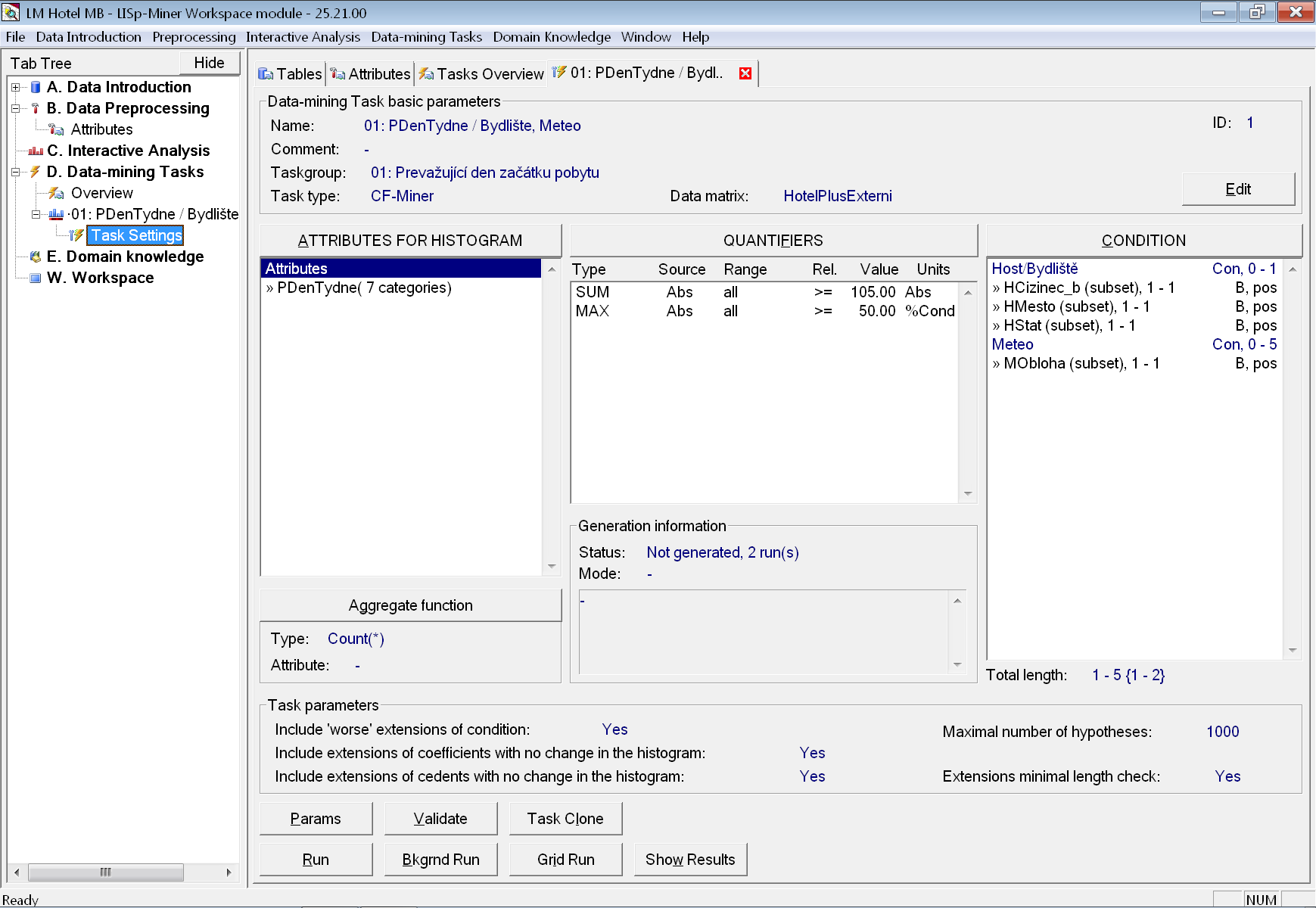
Ukázku úplného zadání úlohy (po provedení všech kroků uvedených níže) vidíme na obrázku.
Do seznamu atributů vlevo byl vložen pouze atribut PDenTydne.
Jedná se o typický způsob zadání úlohy pro CF-Miner. Do seznamu je sice možné zadat atributů více, ale výsledky úlohy potom obsahují celou řadu různých histogramů a pro zodpovězení většiny formulovaných analytických otázek jsou nepřehledné.
Účelem CF-kvantifikátorů je popsat, jaký tvar histogramu považujeme vzhledem k formulované analytické otázce za zajímavý.
V tomto případě jde o požadavek, že maximální frekvence v histogramu (nejčetnější den začátku pobytu) má představovat alespoň 50 % součtu frekvencí za všechny dny. Pro jeho zadání se hodí jednoduchý frekvenční CF-kvantifikátor. V dialogovém okně vyvolaném tlačítkem QUANTIFIERS stiskneme Add simple frequencies quantifier a výše definovaný požadavek zadáme pomocí výběru správné míry zajímavosti (Max frequency), operace porovnání (Greater than or equal) a zadáním prahové hodnoty (50).
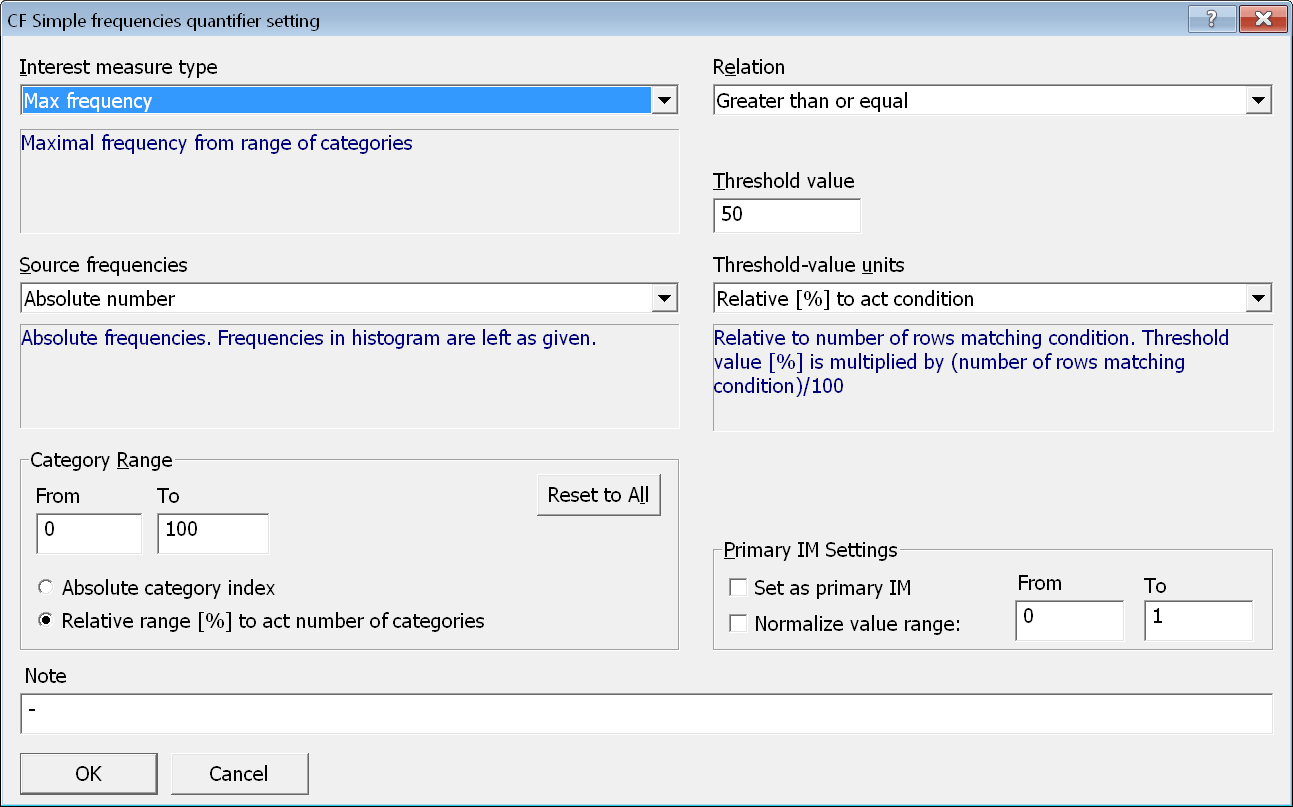
Protože se podmnožiny dat budou generovat jako všechny možné kombinace údajů o bydlišti hosta a o počasí, tak je vhodné zajistit, že právě vygenerovaná podmnožina je dostatečně četná, aby na ní vůbec mělo smysl histogram počítat.
To zajistíme pomocí dalšího jednoduchého frekvenčního CF-kvantifikátoru s mírou zajímavosti Sum of frequencies a vhodnou prahovou hodnotou. CF-kvantifikátor tohoto typu je součástí téměř všech zadání úlohu, a proto se objeví automaticky v každé nově přidané úloze pro CF-Miner. Přednastavená prahová hodnota je 20, což je naprosté minimum a obvykle bude nutné ji zvýšit. V tomto případě ji zvýšíme na 105 v absolutní hodnotě (v průměru alespoň 15 pobytů na jeden den v týdnu).
Podmnožiny dat budeme chtít generovat pro všechny možné kombinace atributů dvou skupin – Host/Bydliště a Meteo. V této ukázce nebudeme pro zjednoduššení vkládat úplně všechny atributy. Z první skupiny vybereme pouze atributy HCizinec_b, HMesto a HStat a ze skupiny počasí dokonce pouze atribut MObloha.
Všimněme si však zadaných minimálních a maximálních délek, jak celé podmínky, tak jednotlivých dílčích cedentů. Minimální délka podmínky byla zvýšena na 1, aby se negenerovala „prázdná“ podmínka a histogram se tak nepočítal na celých datech. Zároveň je však minimální délka u obou dílčích cedentů ponechána na 0, takže z daného dílčího cedentu nemusí být přítomen žádný atribut.
Maximální délka prvního dílčícho cedentu je snížena na 1. To reflektuje skutečnost, že použité tři atributy jsou na sobě závislé (všechny závisí na hodnotě ve sloupci HMesto). Nemá tedy smysl generovat varianty podmínky, kde by se vyskytovaly najednou dva (nebo dokonce všechny tři) atributy z této trojice. Tím zároveň podstatně zrychlíme výpočet úlohy.
U druhého dílčího cedentu zůstala maximální délka na původní hodnotě 5. Protože je však definováno pouze jedno zadání literálu, tak efektivně je maximální délka rovna jedné. A jak vidíme v řádku pod seznamem podmínky, tak efektivní délka generovaných variant podmínky bude jeden až dva literály.
Před spuštěním výpočtu ověříme tlačítkem Validate, že jsme neopomněli žádnou nezbytnou část zadání. Potom spustíme výpočet tlačítkem Run.
Po skončení výpočtu se výsledky zobrazí na záložce Task Results.
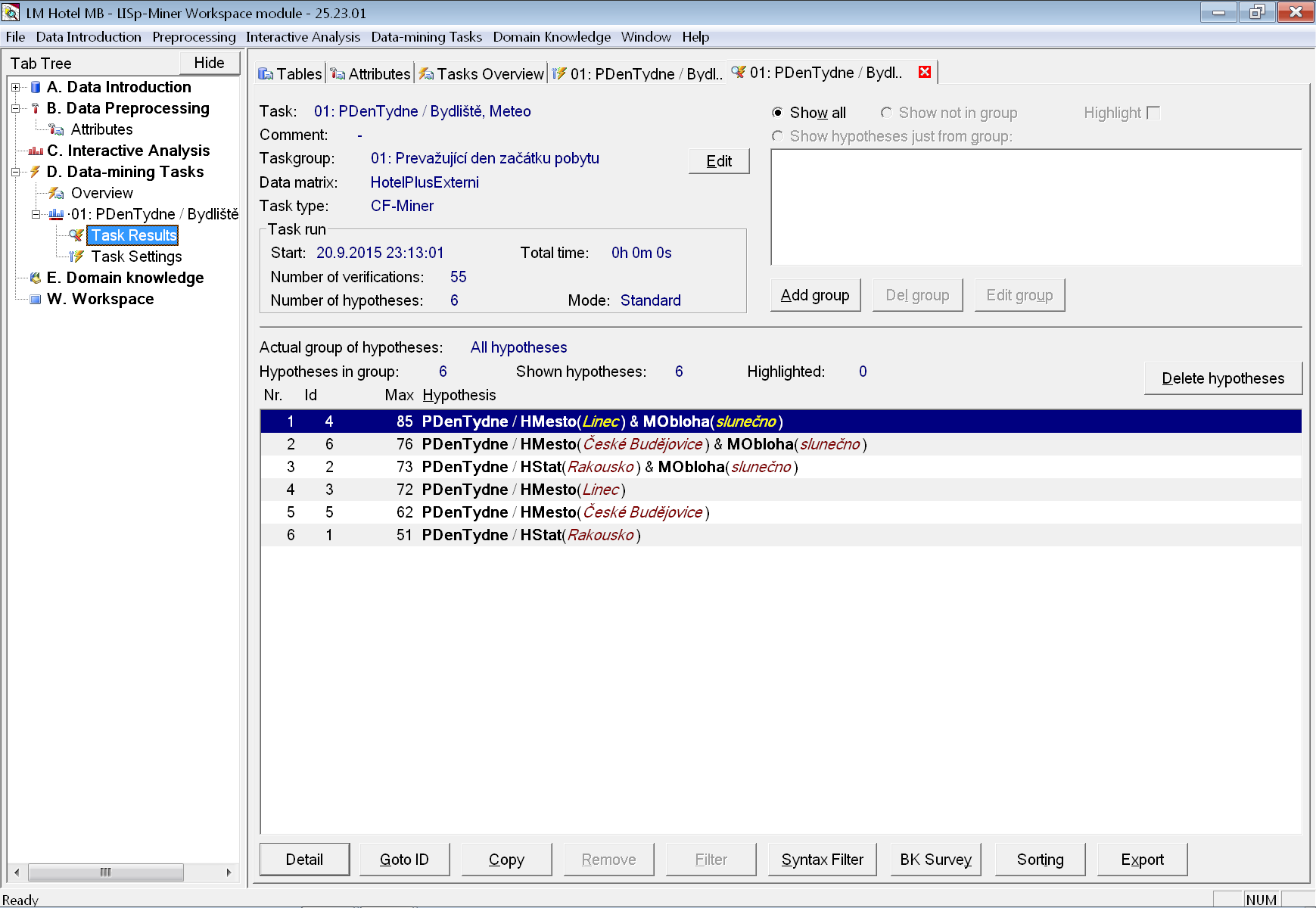
Na obrázku vidíme celkem šest nalezených zajímavých histogramů lišících se podmnožinou dat, na které byly spočítány. Ta je dána kombinací použitých atributů v podmínce.
Postupně si můžeme otevřít detaily jednotlivých nalezených vztahů.
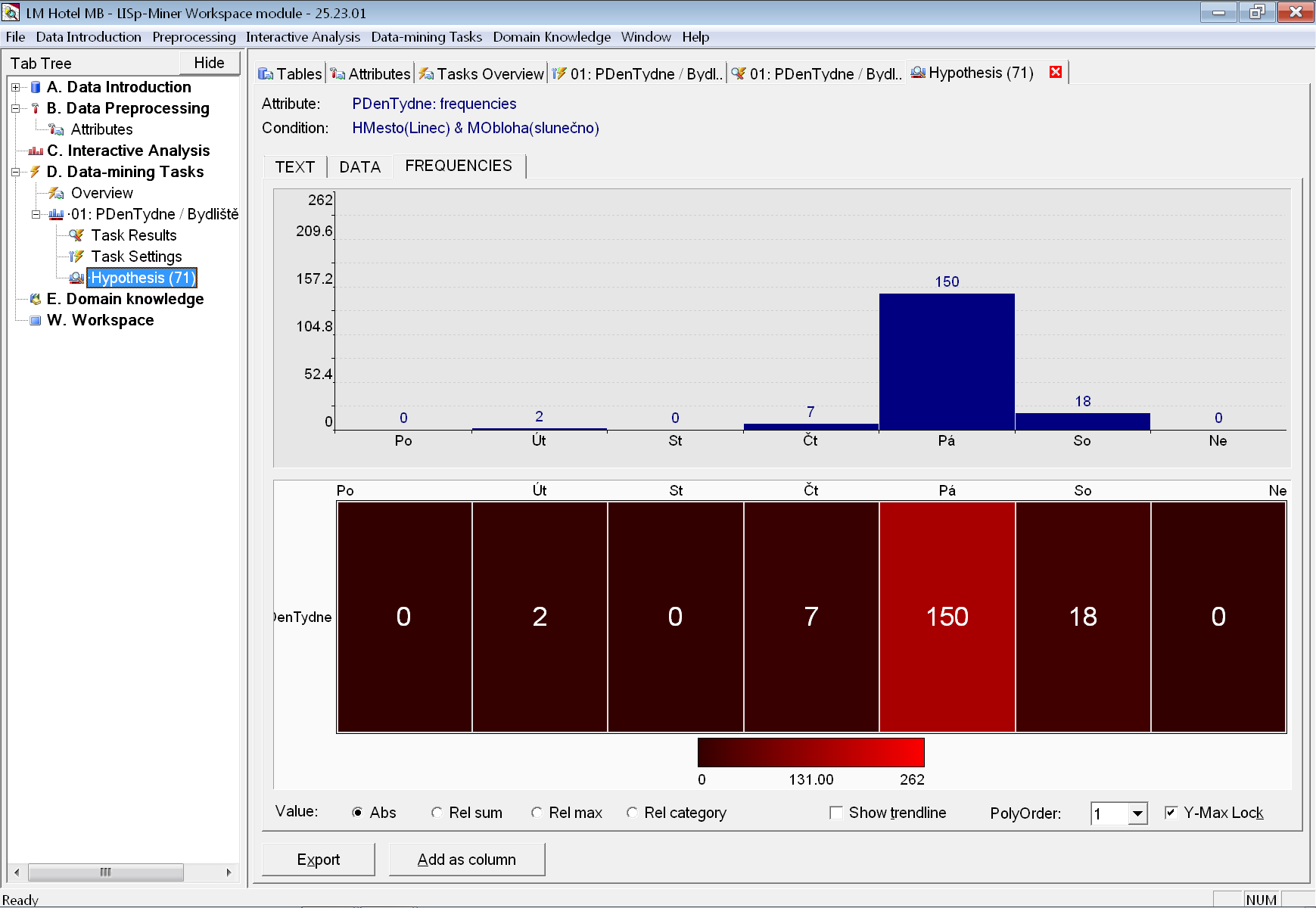
Všimněme si například, že hosté z Lince jezdí převážně v pátek. Na obrázku je ukázka histogramu pro hosty z Lince, kteří přijeli za pěkného počasí. Ti dokonce jezdí téměř jenom v pátek (přesně je to v 85 % případů) a následuje 10 % příjezdů v sobotu (zjistíme snadno přepnutím zobrazení grafu na relativní hodnoty). Z toho lze usoudit, že mají do hotelu blízko a mohou se operativně rozhodnout, zda přijet (pravděpodobně) na víkendový pobyt, či nikoliv. Páteční příjezdy jsou obecně typické po hosty z Rakouska.
Podobně se chovají i hosté z Českých Budějovic. To by odpovídalo pozici hotelu někde na Šumavě, kam mají tyto skupiny hostů blízko.
Všimněme si také, že ve výsledcích se nezobrazují sufixy použité pro vyjádření způsobu předzpracování atributů, které by mohly majitele dat mást. Toho jsme docílili zadáním alternativního názvu atributu.
Toto obvykle není konec hledání odpovědí na položenou analytickou otázku. Většinou se snažíme změnou zadání úlohy (zejména změnami prahových hodnot kvantifikátorů a změnou zadání podmínky) získat další zajímavé vztahy.
V této ukázce se však s nalezeným řešením spokojíme.
Odpověď na první analytickou otázku tedy zní „Pro hosty, kteří mají k hotelu blízko, platí, že většinou přijíždějí v pátek. Pro hosty z Lince a Českých Budějovic je navíc důležitým faktorem slunečné počasí.“
Abychom se nám snáze vypracovávala souhrnná analytická zpráva, vybereme nejzajímavější nalezené výsledky a přesuneme je do souhrnných výsledků všech úloh.
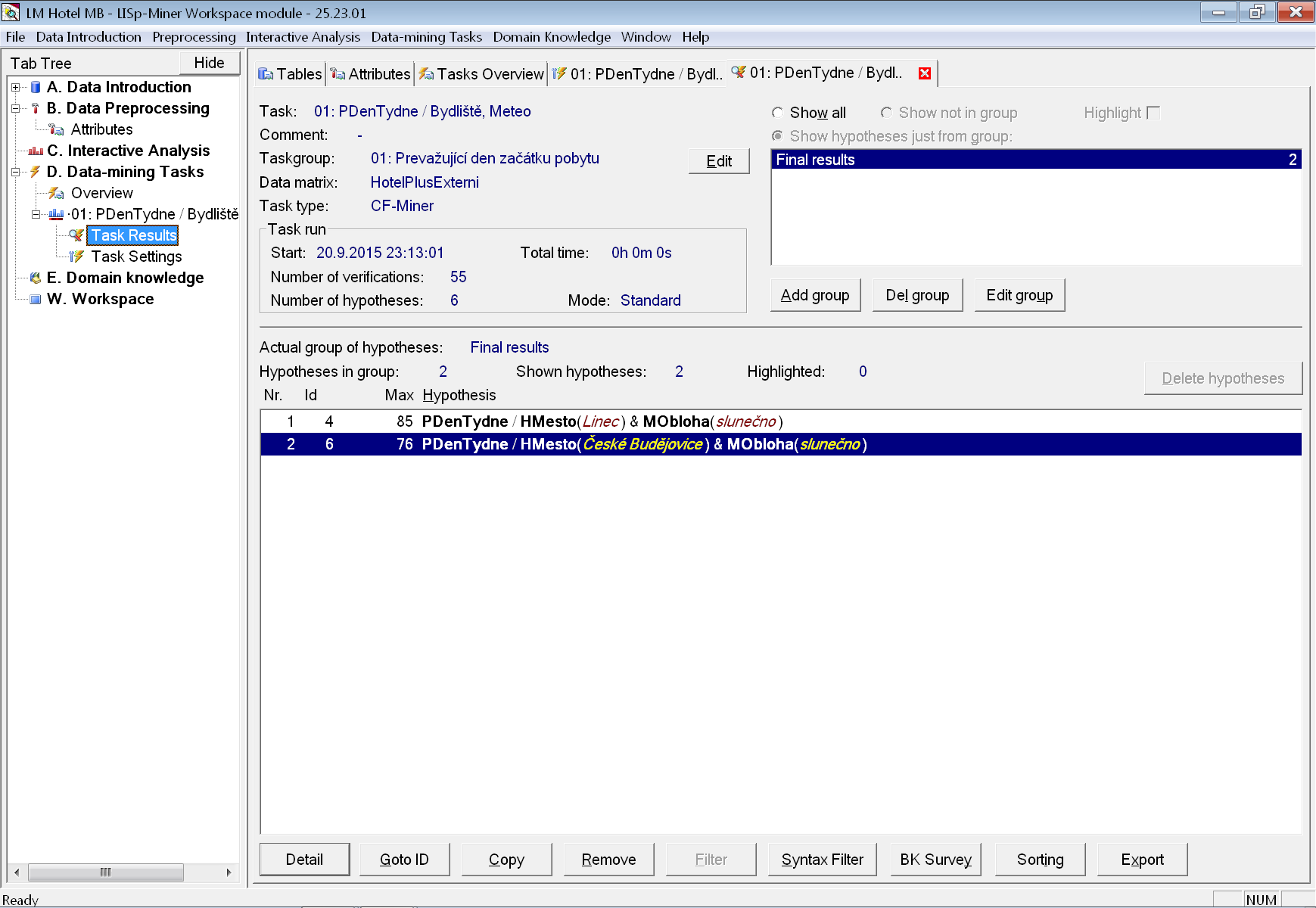
Označíme nalezený vztah pro hosty z Lince přijíždějící za slunečného počasí (nejlepší získaný) a také analogický vztah pro hosty z Českých Budějovic (pomocí klávesy Ctrl). Následně je tlačítkem Copy vložíme do skupiny hypotéz s názvem Final results. Ta zatím ještě nebyla vytvořena, takže ji v dialogovém okně, které se objeví po stisku tlačítka Copy, nejprve vytvoříme pomocí tlačítka Add (název skupiny se automaticky předvyplní). Následně skupinu vybereme, aby se do ní označené vztahy přesunuly.
Na záložce Task Results se přepneme na zobrazení hypotéz pouze z právě přidané skupiny Final results:
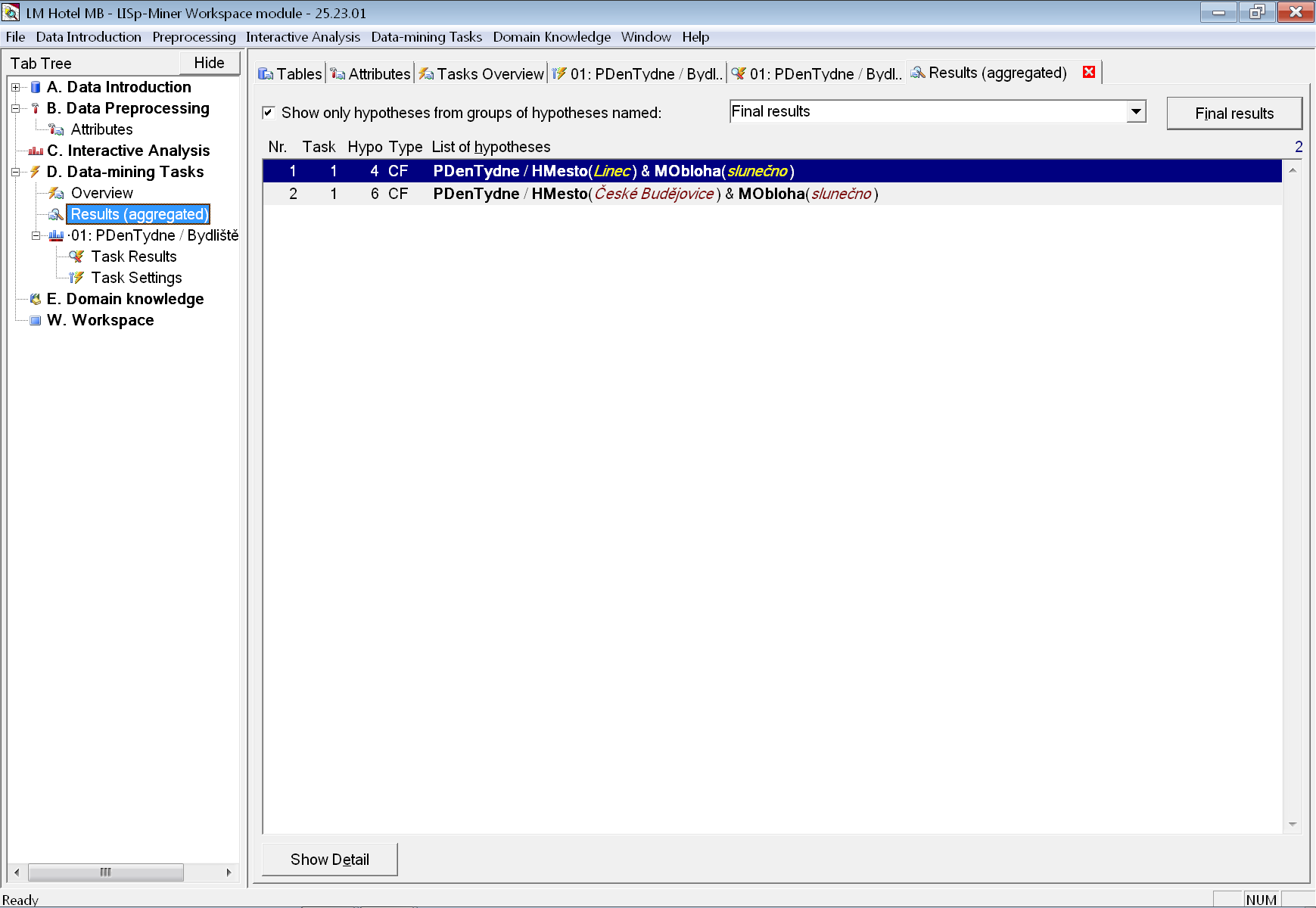
Zároveň můžeme zkontrolovat, že oba vztahy budou na záložce se souhrnnými výsledky i po stisku tlačítka Final results.
Správnost provedených kroků zkontrolujeme pomocí tlačítka Ctrl+F9 a výběrem správné položky ze seznamu šablon pro ověření obsahu metabáze:
![]() MBCV: Demo Hotel 04 DM Tasks 01 CF-Miner (Hotel.MBVC.zip)
MBCV: Demo Hotel 04 DM Tasks 01 CF-Miner (Hotel.MBVC.zip)
Související témata:
