Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Před zadáváním atributů se nezapomeneme nastavit na skupinu Host/Bydliště.
Po stisku tlačítka Add attribute vybereme sloupec HMesto, potvrdíme název HMesto a v dialogovém okně pro automatické vytvoření kategorií ponecháme přednastavenou volbu Each value – one category.
Dále vytvoříme klon atributu HMesto, který nazveme HMesto_m_hlavní. Ten bude obsahovat kategorie pouze pro hlavní města států. To můžeme udělat dvěma způsoby:
Del. Označit všechny kategorie najednou můžeme nastavením na první kategorii v seznamu a stiskutím kombinace kláves Shift+End.Preprocessing zvolíme položku Batch add of categories. Do seznamu v dialogovém okně pro hromadné přidání kategorií zadáme názvy hlavních měst (Berlín, Bratislava, Praha, Varšava a Vídeň) a stiskneme OK.

Pozor! Kategorie nesmíme editovat v původním atributu HMesto, ale až ve vytvořeném klonu HMesto_m_hlavní.
Pozor! Před potvrzením názvu kategorií zkontrolujeme, že za žádným z názvů není zapomenutý znak mezera.
Úplně stejně postupujeme i v případě atributu HStat (sloupec: HStat, kategorie: Each value – one category).
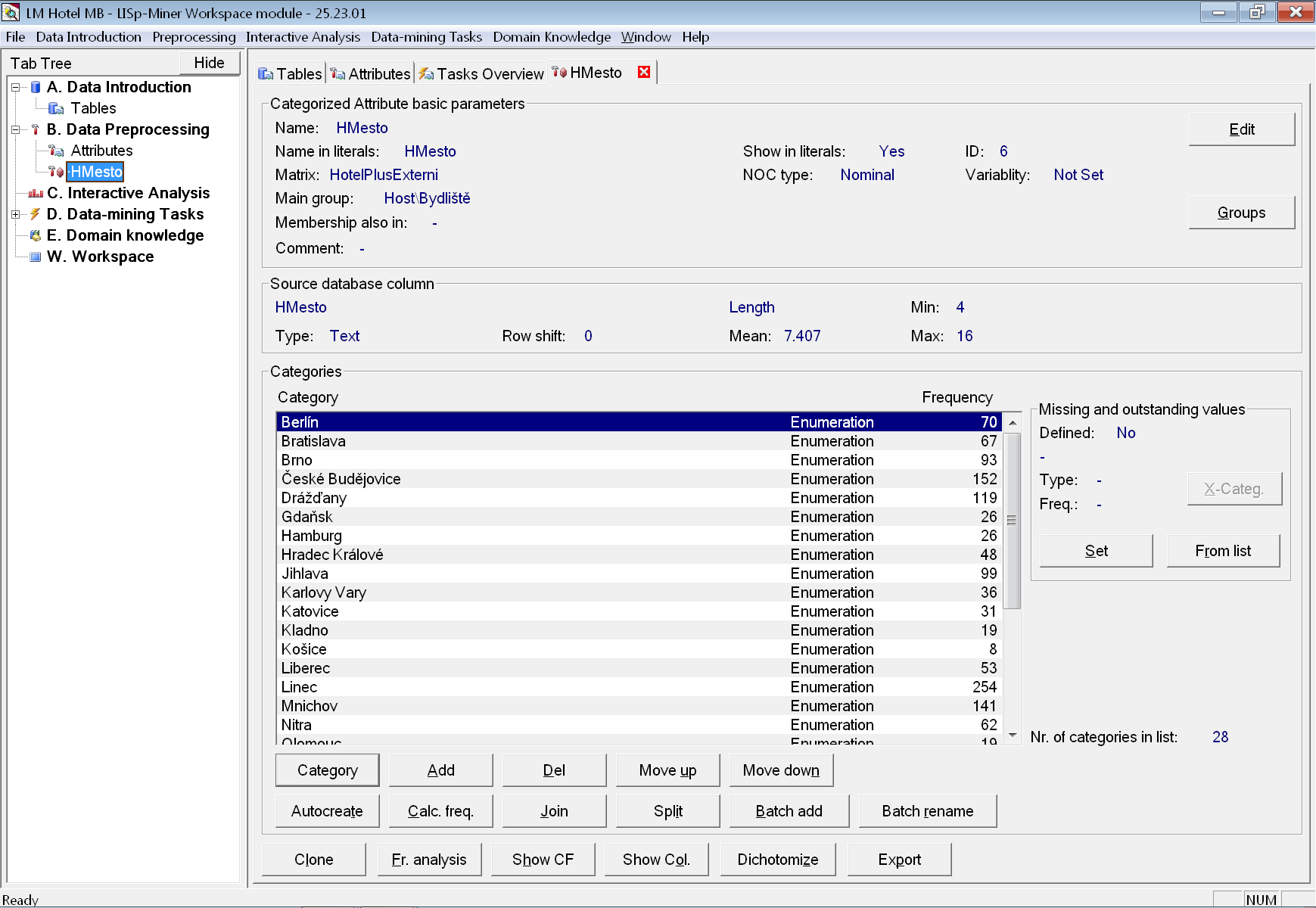
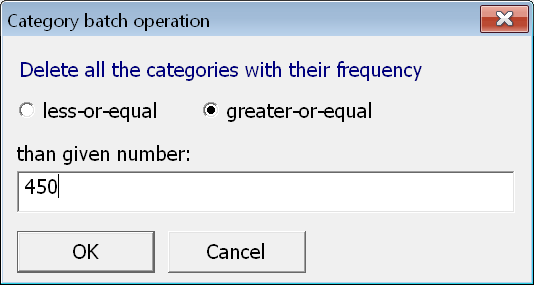
Po zobrazení frekvencí kategorií právě vytvořeného atributu vidíme, že hosté z České republiky převažují. V takovém případě je obvykle vhodné zkoumat zvlášť hodnoty bez nejčetnější. Pro tento účel si připravíme klon atributu HStat, který pojmenujeme HStat_m_bezČR a v tomto nově vytvořeném atributu vymažeme pomocí tlačítka Del kategorii ČR.
 Kdybychom chtěli vymazat více kategorií s velkou četností najednou, mohli bychom v menu
Kdybychom chtěli vymazat více kategorií s velkou četností najednou, mohli bychom v menu Preprocessing zvolit Batch delete of categories by frequency. Po stisku tlačítka OK se smažou všechny kategorie, které mají frekvenci vyšší, než je zadaný práh. Četnosti zjistíme v seznamu kategorií. Je-li místo frekvence pouze otazník, stačí stisknout tlačítko Calc. freq..
Pozor! Kategorii ČR nesmíme smazat v původním atributu HStat, ale pouze ve vytvořeném klonu HStat_m_bezČR.
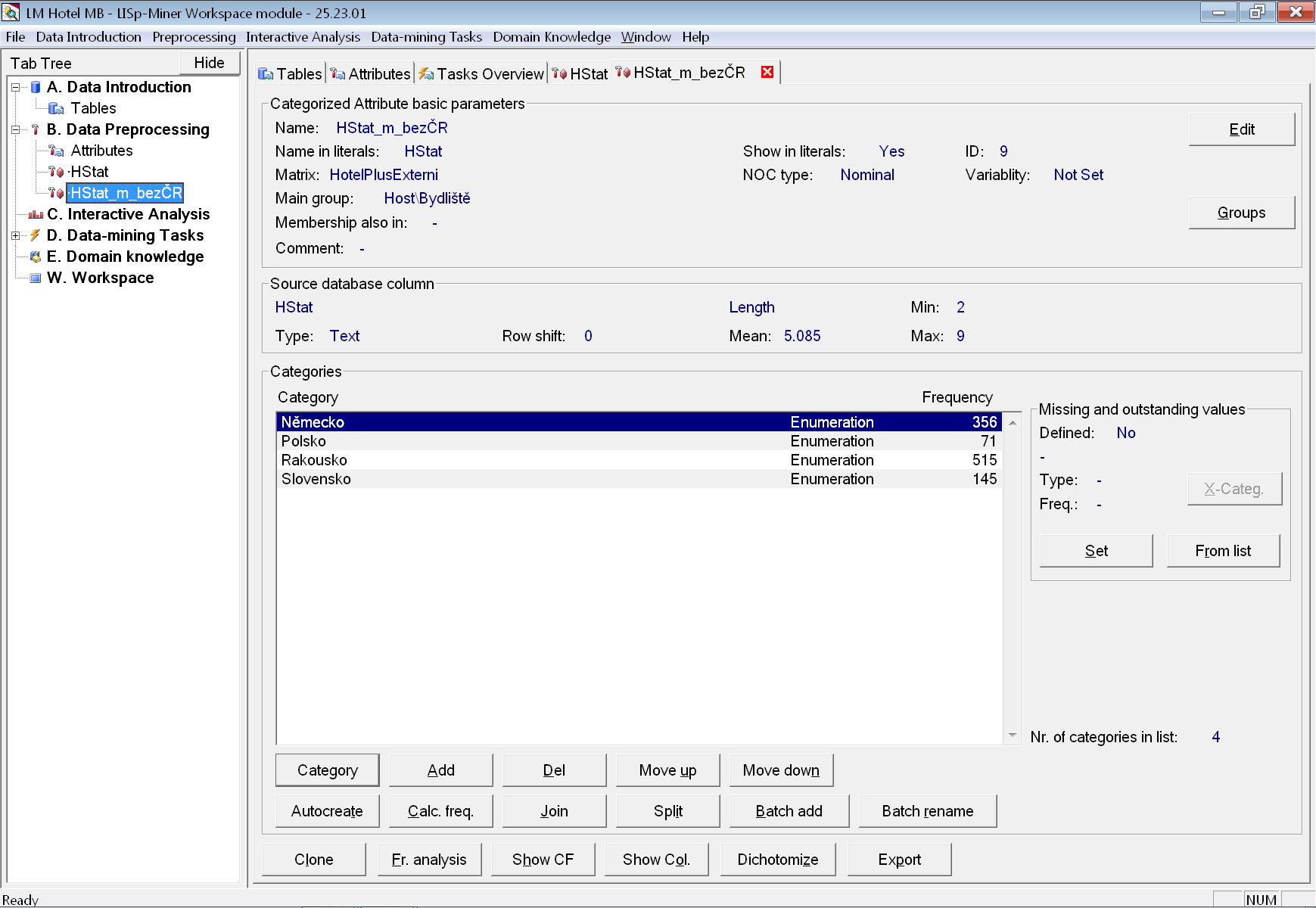
Sloupec HCizinec v datech nemáme, ale cizince od hostů z ČR snadno rozlišíme podle hodnoty ve sloupci HStat. Binární atribut HCizinec_b navíc snadno vytvoříme jako klon dříve vytvořeného atributu HStat.
Pozor! Po změně názvu atributu je třeba zkontrolovat i alternativní název, který se má používat při interpretaci.
Na záložce nově vyklonovaného atributu HCizinec_b označíme v seznamu kategorií všechny kromě ČR a pomocí tlačítka Join je spojíme v jednu. U binárního atributu obvykle očekáváme dvě kategorie pojmenované ano a ne. Proto pomocí tlačítka Batch rename opravíme názvy obou kategorií najednou. Pečlivě zkontrolujeme, že jako ne pojmenuje kategorii obsahující hodnotu ČR a jako ano sloučenou kategorii obsahující hodnoty Německo, Polsko, Rakousko a Slovensko.
Zároveň bývá zvykem, že u binárních atributů je pořadí kategorií ne (někdy též 0), a potom ano (někdy též 1). Pomocí tlačítek Move up a Move down bychom mohli pořadí opravit, ale v tomto případě je rovnou správně.
Informaci o kraji, ze kterého host pochází, jsme do dat přidali jako odvozený sloupec vypočtený z geografických dat a pojmenovali HKraj.
Atribut stejného jména nad ním vytvoříme velmi jednoduše postupem shodným jako u
atributů HMesto a HStat – kategorie vytvořeny pomocí volby Each value – one category.
Stejně jednoduše přidáme i atribut HNejblizsiHotelNazev, který vytvoříme nad takto pojmenovaným odvozeným sloupcem. Kategorie budou opět vytvořeny pomocí volby Each value – one category.
Související témata:
![]() Demo Hotel: Vytvoření atributů ve skupině Pobyt
Demo Hotel: Vytvoření atributů ve skupině Pobyt
![]() Demo Hotel: Vytvoření atributů a jejich kategorií
Demo Hotel: Vytvoření atributů a jejich kategorií
![]() Atribut a jeho kategorie
Atribut a jeho kategorie
