Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Začínáme
Systém LISp-Miner a proces DZD
Analytické procedury
Pokročilé funkce
Výzkum a vývoj
Databázové pohledy (angl. database view) jsou „dynamické“ tabulky, jejichž obsah je vytvářen až na základě požadavku s pomocí hodnot z existujcích databázových tabulek nebo databázových pohledů. Jde vlastně o předdefinovanou podobu dotazu SELECT do databáze, ve kterém můžeme použít spojování tabulek, vybrat pouze některé sloupce a případně i omezit počet záznamů. Z pohledu DZD jde o činnosti patřící do fáze Předzpracování dat.
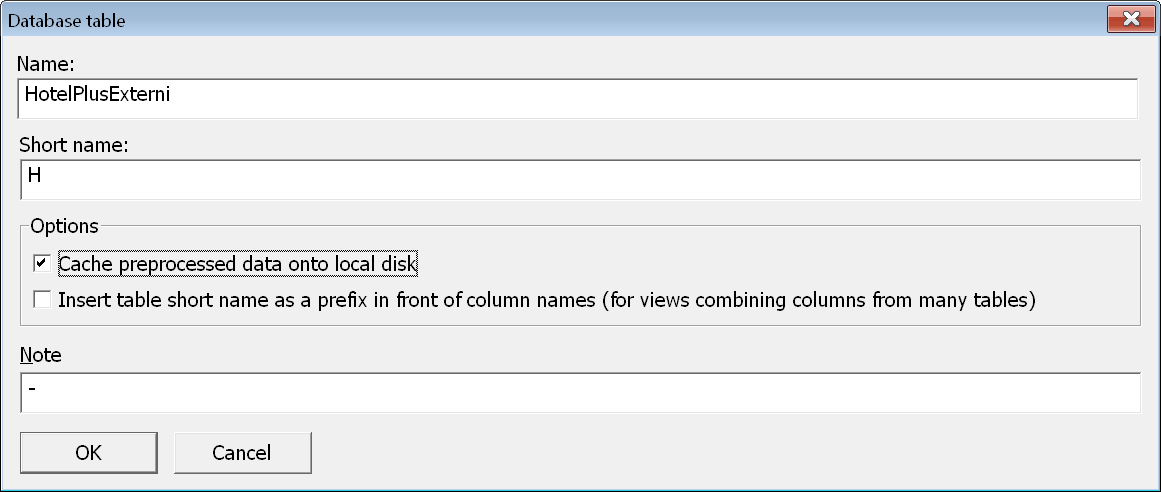 Nový databázový pohled přidáme pomocí tlačítka
Nový databázový pohled přidáme pomocí tlačítka Add View na záložce Tables. Objeví se dialogové okno pro zadání názvu nově vzniklého dynamického pohledu. Tento název musí být unikátní a zároveň by měl být dostatečně výstižný.
U právě přidávaného pohledu můžeme povolit vytváření lokální cache dat. Zejména v tomto případe doporučujeme vytváření cache povolit, abychom ušetřili čas spotřebovaný opakovaným spojováním více tabulek pomocí klauzule WHERE.
Dále můžeme zvážit, zda se má před názvy sloupců předřadit název tabulky, ze které pocházejí. To může být potřeba v případě, že chceme odlišit stejně pojmenované sloupce v tabulkách, které spojujeme. V takovém případě doporučujeme zaškrtnout příslušnou volbu.
Po stisku tlačítka Ok se objeví dialogové okno pro nastavení základní zdrojové tabulky a použitých relací.
V systému LISp-Miner musí mít každý definovaný pohled vybranou jednu databázovou tabulku jako „základní“. Ta se vybírá ve volbě Main Parent database table) a určuje první tabulku, která bude uvedena v klasuli FROM dotazu SELECT definujícího tento pohled.
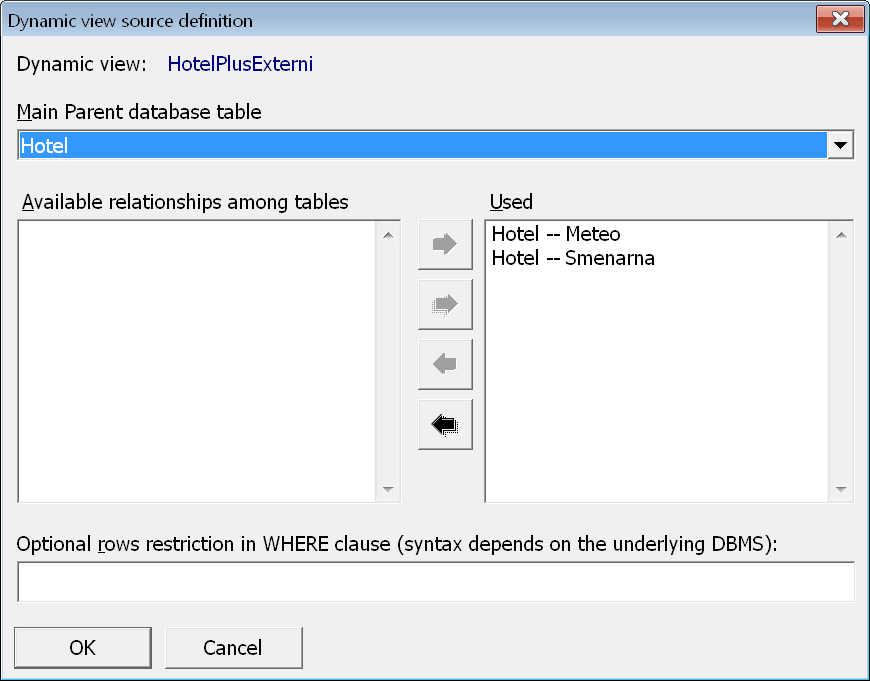 Realizujeme-li pomocí databázového pohledu propojení dat z více tabulek, musíme z dříve nadefinovaných relací vybrat ty, které vedou od základní zdrojové tabulky k tabulkám dalším. Výběr relace provedeme jejím přesunutím z levého seznamu do pravého.
Realizujeme-li pomocí databázového pohledu propojení dat z více tabulek, musíme z dříve nadefinovaných relací vybrat ty, které vedou od základní zdrojové tabulky k tabulkám dalším. Výběr relace provedeme jejím přesunutím z levého seznamu do pravého.
Vybrané relace se použijí v klauzuli WHERE příkazu SELECT. Při jejich výběru je třeba zajistit, že ke všem v nich odkazovaným tabulkám vede jednoznačná „cesta“ od základní zdrojové tabulky. V opačném případě budeme na na tuto chybu upozorněni. Typickou strukturou používanou při propojování dat z více tabulek je je struktura hvězda mající relace pouze mezi hlavní tabulkou a vždy jednou tabulkou s externími daty (o počasí, o ekonomice…).
Výběr použitých relací můžeme později opět vyvolat pomocí tlačítka View Def na záložce s detailem tabulky/databázového pohledu. Doporučujeme však, aby definice použitých relací byla dobře rozmyšlena dopředu a po vytvoření dynamického pohledu (a zejména po vytvoření nad ním založených atributů) už nebyla měněna.
Nebudou-li v databázovém pohledu potřeba data z žádné jiné tabulky, než je základní zdrojová, není třeba žádné relace vybírat.
Volitelně můžeme u databázového pohledu omezit počet záznamů. Zadaná podmínka se přidá do klauzule WHERE příkazu SELECT a její správná syntaxe je tak závislá na použitém DBMS.
S vytvořeným databázovým pohledem můžeme pracovat úplně stejně, jako s kteroukoliv databázovou tabulkou.
Databázový pohled se objeví v seznamu na záložce Tables. Můžeme si pro něj zobrazit záložku s detaily a vytvářet nad ním atributy.
V prvé řadě je třeba pohled inicializovat tím, že otevřeme záložku s přehledem sloupců. Následně je třeba ručně označit primární klíč pomocí tlačítka Set Primary key.
Pozor! Zejména u databázových pohledů propojujících data z více tabulek je třeba pečlivě kontrolovat, který sloupec označujeme jako primární klíč. Obvykle půjde o sloupec s názvem ID nebo ID_LM, které se však mohou vyskytovat ve všech spojovaných tabulkách! Správný sloupec obvykle bývá ten převzatý ze základní zdrojové tabulky.
Související témata:
![]() Zadání vztahů mezi tabulkami
Zadání vztahů mezi tabulkami
![]() Seznam databázových tabulek
Seznam databázových tabulek
![]() Praktická ukázka: Demo Hotel: Propojení tabulek
Praktická ukázka: Demo Hotel: Propojení tabulek
